Test • AMD Zen 2 : X570 & Ryzen 7 3700X / Ryzen 9 3900X |
————— 07 Juillet 2019



Test • AMD Zen 2 : X570 & Ryzen 7 3700X / Ryzen 9 3900X |
————— 07 Juillet 2019
Après Zen, qui marque la renaissance d'AMD dans la course à la performance côté CPU, nous avons eu droit à un Zen+. Cependant, l'agencement interne n'a pas vu de changement : seul un passage au 12 nm s'est effectué, ce qui a néanmoins grandement corrigé les défauts de jeunesse, à savoir une compatibilité mémoire limitée, la latence d'accès à cette dernière et un retard conséquent en fréquence face à la concurrence bleue. Cette mouture mérite donc à juste titre sa numérotation pour ce qui est des changements architecturaux, au prix d'une obscuration des termes, puisque la série 3000 répond au nom de Zen 2 si on exclut les séries G.
Pour cette mise à jour, AMD fait coup double. Au contraire d'un Tick-Tack-Tock-Tock-Tock enroué, les rouges ont simultanément effectué un saut dans les finesses de gravure avec le passage au 7 nm en UV profonds, et une révision majeure de sa micro architecture, avec entre autres l’arrivée tonitruante des chiplets hors du segment HEDT. L'agencement général ne comporte pas de modification structurelle - nous vous invitons à relire la partie consacrée à ce sujet dans notre dossier sur Zen - nous voyons mal comment il aurait pu en être autrement. Il faut dire que les plateformes x86 et ARM semblent converger vers ce design, découpant les instructions après décodage en micro-opérations, elles-mêmes affectées à différents ports plus ou moins spécialisés.
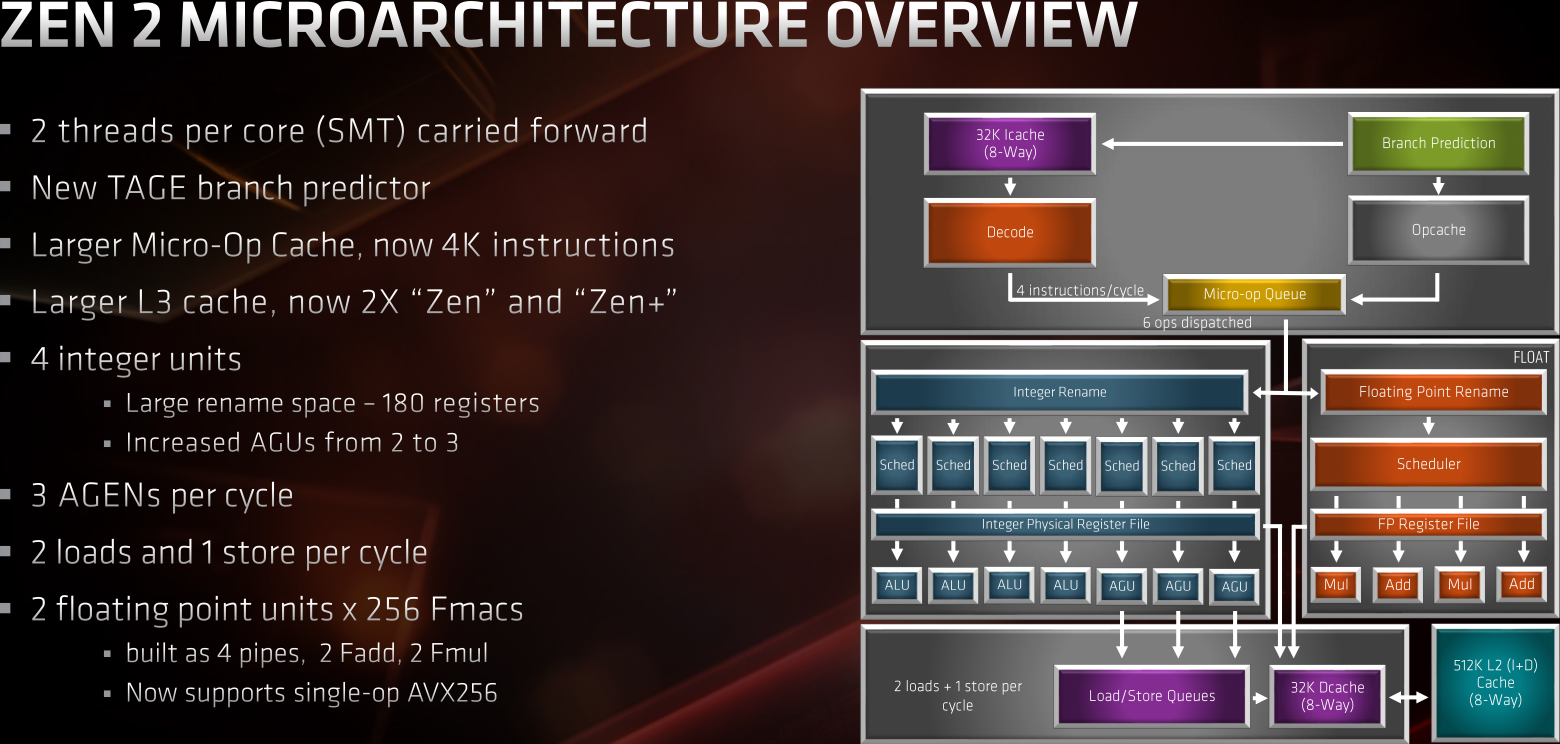
![zen 2 micro architecture [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-microarch_t.png "Ultra bouzotron HD max def")
Pas de surprise, le SMT a deux voies est conservé, par contre AMD annonce avoir travaillé sur à peu près tout le contenu du CPU : aussi bien l'étage de décodage et de lecture des instructions que sur les ports de calcul entier, mais surtout flottant, en se mettant à jour par rapport à Skylake, sujet sur lequel nous reviendrons un peu plus loin.
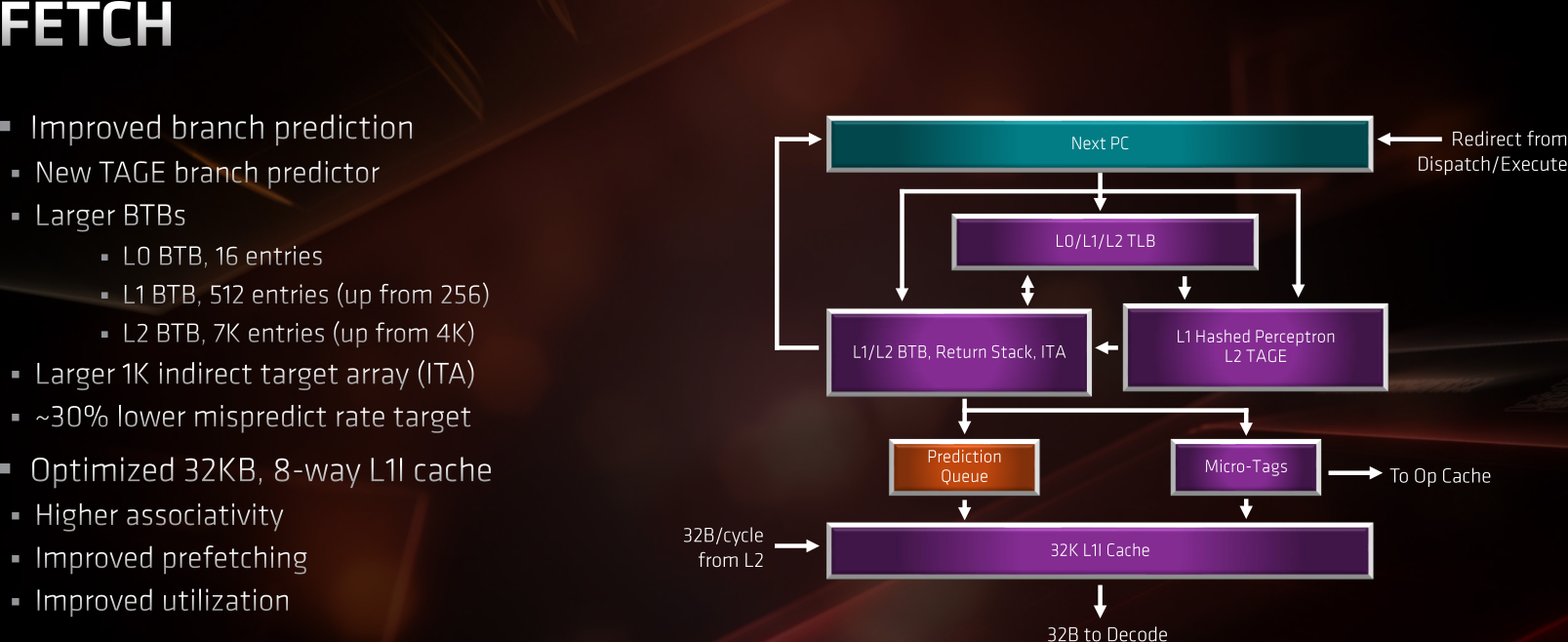
La partie de chargement des instructions, premier étage du pipeline d'exécution d'un CPU, voit quelques améliorations mineures. Le prédicteur de branchement de Zen, basé sur un réseau de neurones, est abandonné pour une version déterministe nommée TAgged GEometric (TAGE). Une implémentation développée au niveau recherche vers 2006 en France, pour l’anecdote. Les caches nécessaires à ces prédictions (BTB, pour Branch Target Buffer) de niveau 1 et 2 suivent une augmentation, de quoi améliorer les performances pour les codes présentant un nombre important de sauts.
![zen2 prédicteur de branchement [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-fetch_t.png "Si vous cliquez, vous cliquez.")
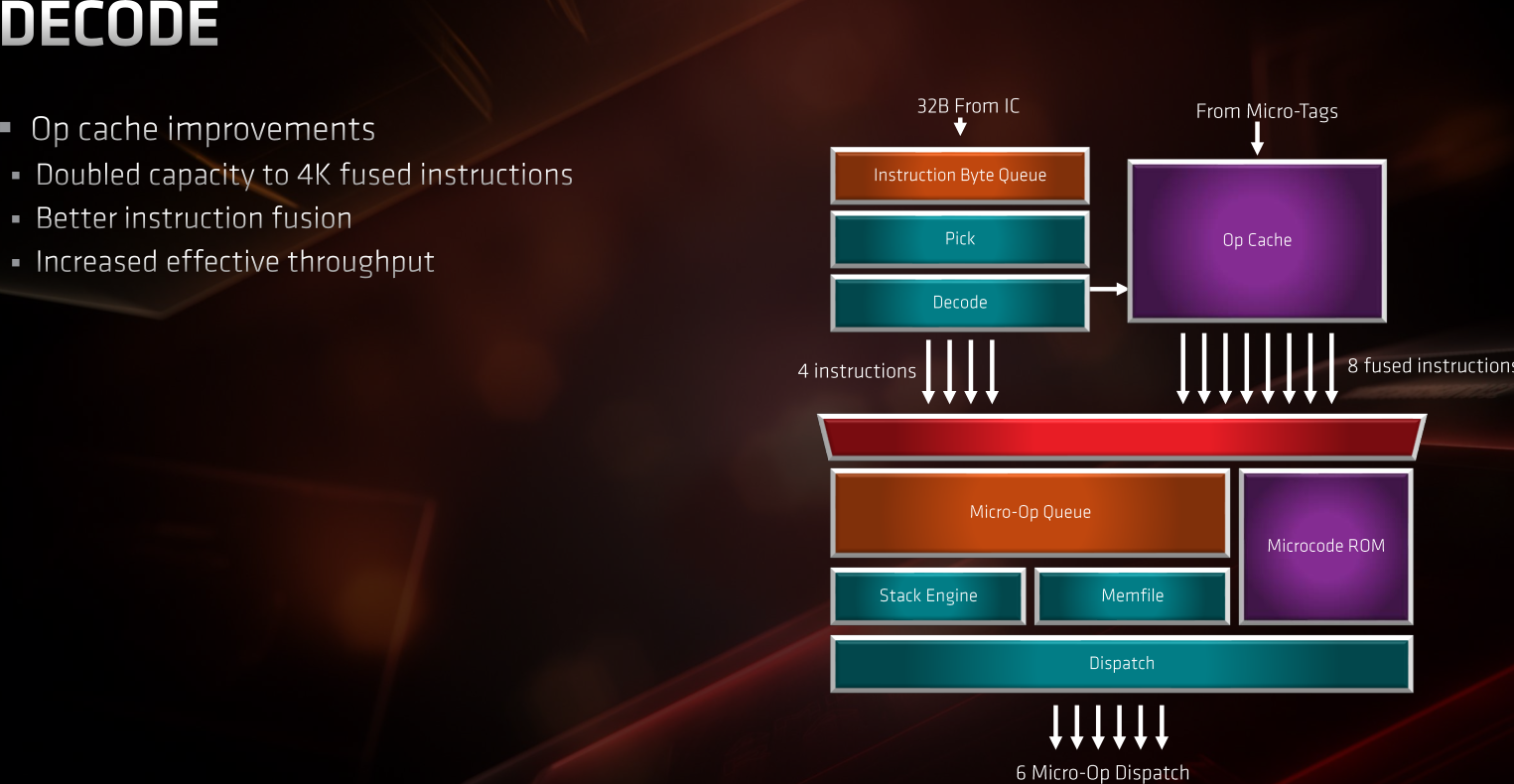
Passons désormais à l'étage de décodage, où les instructions x86 sont découpées en micro-opérations RISC. Pas de grandes modifications mis à part l'élargissement du cache des micro-ops (issues de la sortie du prédicteur de branchement) qui passe de 2k à 4k entrées.
![zen2 décodeur (comme canal +, ouais !!) [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-dispatch_t.png "Enlarge your pe...icture")
Un des grands changements par rapport à Zen premier du nom, est l'élargissement du débit de calcul des opérations flottantes, mise à jour rattrapant le retard sur Skylake. Désormais, Zen 2 est capable d'assurer un débit de 256 bits par cycle, contre la moitié pour Zen. Il en résulte une augmentation globale des performances en AVX, puisque ces extensions manipulent justement des vecteurs flottants sur 256 bits. De plus, la latence de la multiplication flottante passe à 3 cycles, un ajout toujours bon à prendre.
![zen2 calcul des opérations flottantes [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-fpu_t.png "Visionner en grand sur un magnifique pop-up")
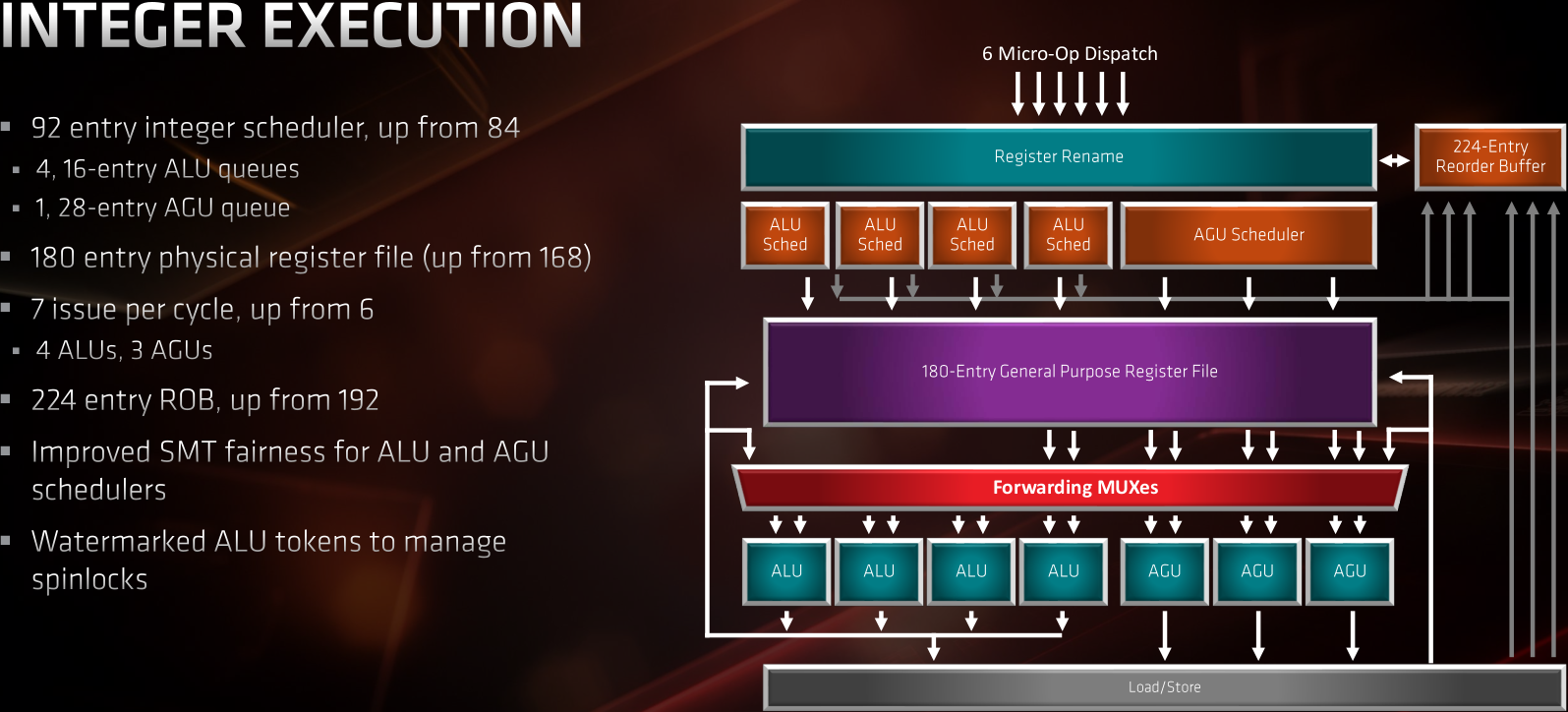
Qui dit élargissement du débit de calcul, dit aussi élargissement de la bande passante mémoire : il faut bien charger les données de quelque part ! Cela commence par les unités de calcul entier, qui sont également utilisées pour le calcul d'adresse. Ici aussi, la structure rattrape Skylake : trois ports de calculs d'adresse (contre 2 sur Zen) et 4 pour le calcul entier (pas de changement). Au passage, les unités de répartition des micro-opérations et le tampon de ré-ordonnancement de ces micro-opérations, sont élargis avec respectivement un passage de 84 à 92 entrées et de 192 à 224 entrées.
![zen2 calculs entiers [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-int_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
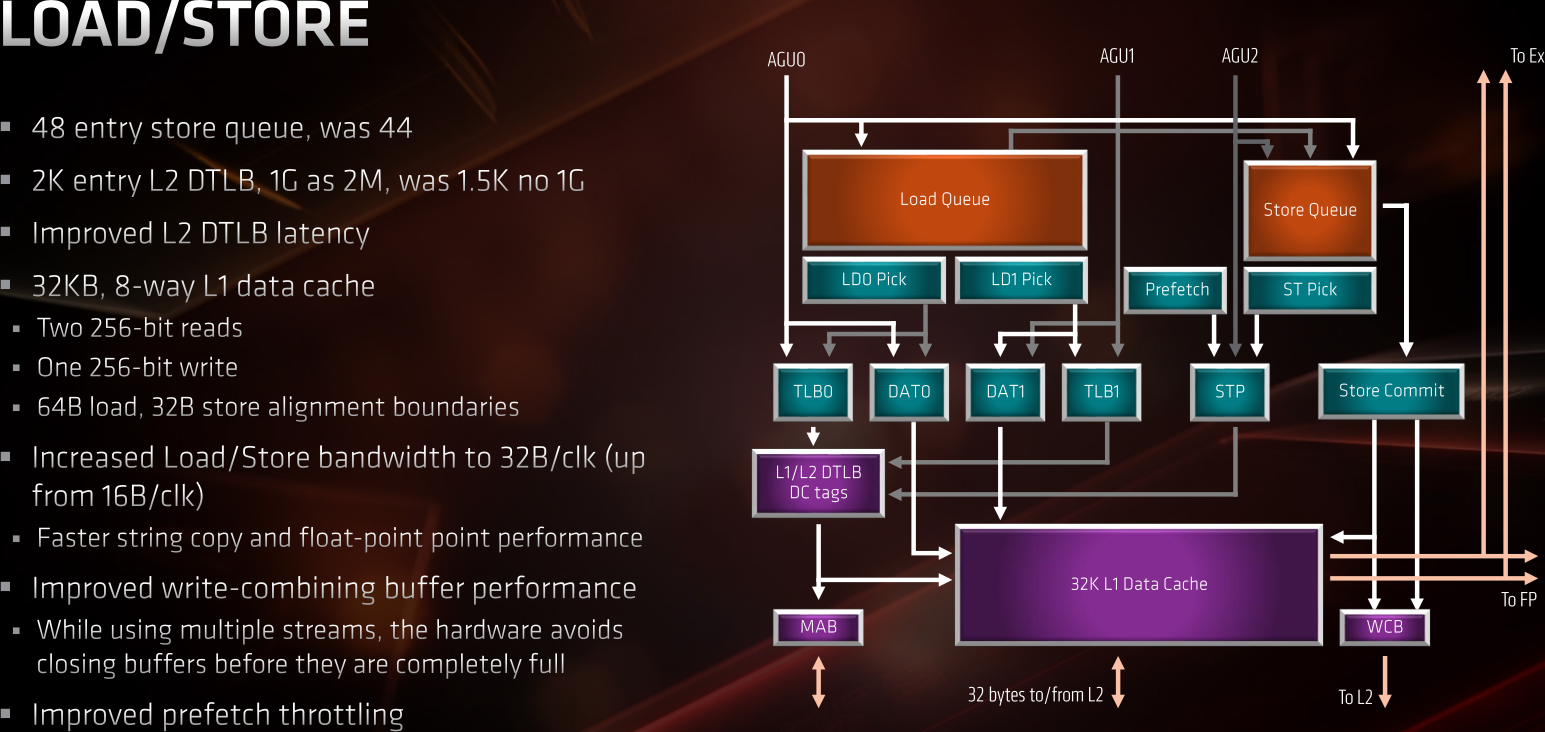
Par souci d'équilibrage du CPU, le sous-système mémoire est lui aussi revu... et copie celui de Skylake, encore une fois : deux unités de lecture et une d'écriture, toutes assurant un débit de 256 bits par cycle (soit 32 octets), contre deux unités de lecture-écriture fusionnés @ 16o/cycle auparavant.
![zen2 sous-système mémoire [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-load-store_t.png "Enlarge your pe...icture")
C'en est fini pour la partie calcul de Zen 2, destination mémoire à la page suivante.
|
|
| Un poil avant ?Test • AMD RX 5700 XT & RX 5700 | Un peu plus tard ...Bon plan • Le Ryzen 7 3700X à 338,31 € (préco) | |