Test • AMD Zen 2 : X570 & Ryzen 7 3700X / Ryzen 9 3900X |
• 07 Juillet 2019



Test • AMD Zen 2 : X570 & Ryzen 7 3700X / Ryzen 9 3900X |
• 07 Juillet 2019
Alors que Zen 1/+ arborait ses 8 Mo de L3 par die, Zen 2 joue la surenchère avec un doublement de cette capacité, mais un accès plus difficile de par un cloisonnement encore plus prononcé entre dies. Comment tout cela fonctionne-t-il ? Voyons cela ensemble.
![zen2 cache [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-ccx_t.png "Enlarge your pe...icture")
Sur la structure générale, rien ne semble changer à première vue : un Core Complex (CCX) est toujours composé de 4 cœurs (et 8 threads), 512 Ko de L2 privé par cœur, 32 Ko de L1. Toutefois, AMD le dote de 16 Mo de L3 en lieu et place des 8 Mo de Zen premier du nom, un changement conséquent pour le coup.
Un des goulots d'étranglement de Zen était l'Infinity Fabric, l’interconnexion qui permet de conserver la cohérence de cache. Une variable peut ainsi faire un saut entre le L3 d'un CCX vers un cœur d'un autre CCX. Mais cela se paie cher, à la fois en latence et en conséquence sur l'overclocking, car il est difficile de faire monter en fréquence ce système. Pour Zen 2, AMD a été radical : le L3 est désormais totalement privé par CCX, c'est-à-dire que des groupes de 3 ou 4 cœurs (selon le modèle) partagent 16 Mo de L3 épicétout, même si votre CPU en contient en tout 64 Mo. Cela n'a cependant rien de choquant, puisque c'est déjà la manière de compter le L2 (512 Ko par cœur, compté comme 2 Mo de L2 sur un quad-core).
Par contre, cela explique le pourquoi du doublement de sa taille, qui permet aux applications monothreads de se retrouver avec autant de cache L3 que sur Zen, et donc de ne pas afficher de dégradation de performance dans ce cas de figure ! Si vous suivez, cela signifie aussi que Zen 2 est plus prompt à grimper en fréquence que Zen, en dépit d'une nouvelle finesse de gravure pas forcément maîtrisée à la perfection.
![zen2 archi logique du cache [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-chip-2ccd-logic_t.png "Si vous cliquez, vous cliquez.")
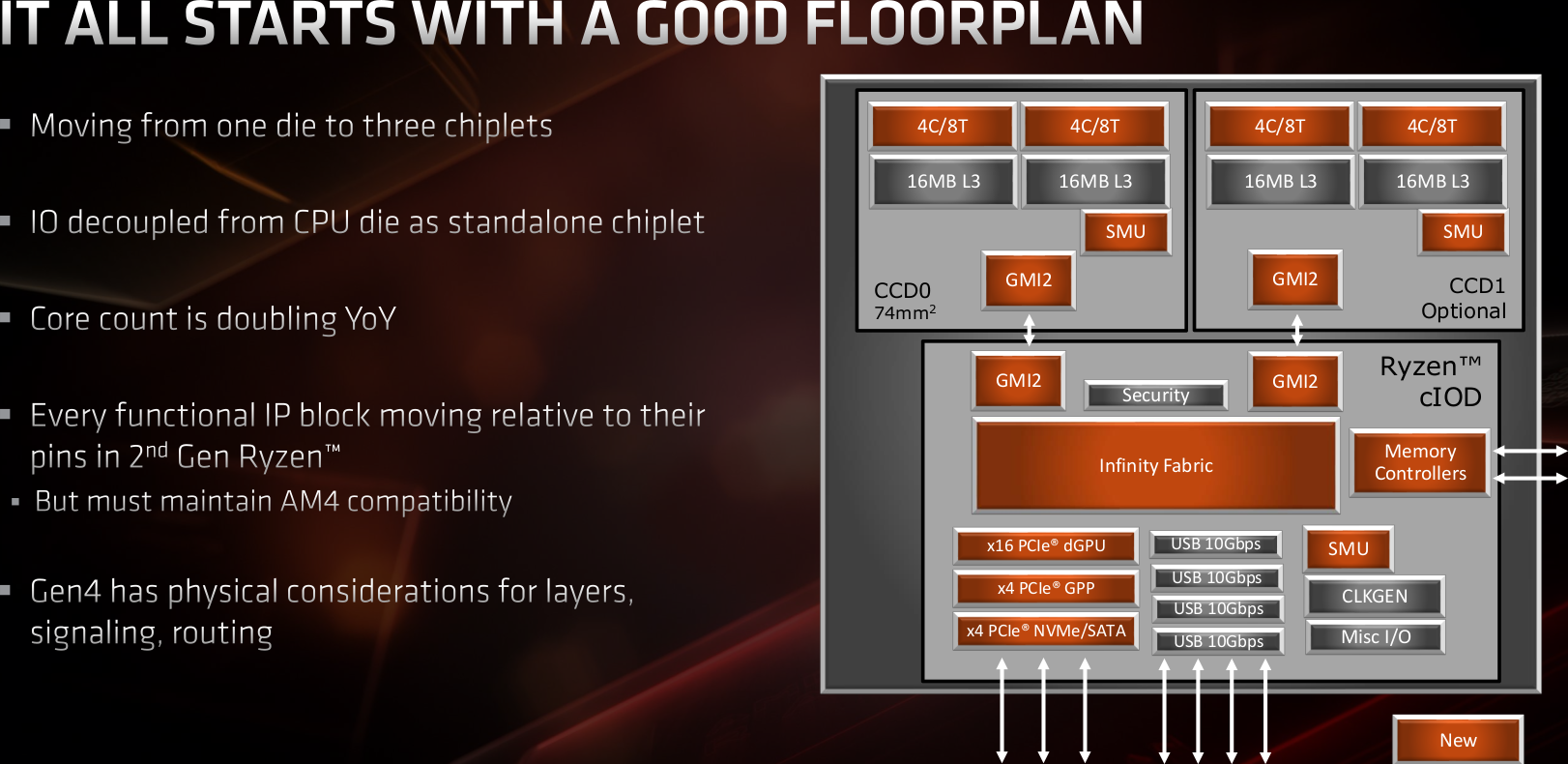
Avec les dies, l'encapsulation continue en introduisant la notion de chiplet. Ils peuvent être de 2 types pour cette génération : le premier est composé de deux CCX formant ce qu'AMD nomme un CCD, pour Compute Die. Chaque processeur Zen 2 est également composé d'un cIOD (le die d'entrée/sortie) gravé en 12 nm. À ce dernier, s'ajoute donc un ou deux CCD utilisant cette fois le process 7 nm. Bien que la taille du cIOD soit plus importante que celle des CCD, du fait du différentiel de densité lié aux processus de fabrication respectifs, les caches sont physiquement bel et bien dans le dernier cité. Le cIOD ne contient "que" les entrées/sorties directes qui évitent le chipset : PCIe, NVMe, SATA, USB, et bien sûr le contrôleur mémoire capable de gérer deux canaux. On reconnaîtra en fait dans ce die une nouvelle incarnation du Northbridge-Southbridge fusionné, comme quoi l'informatique finit par revenir à ses sources !
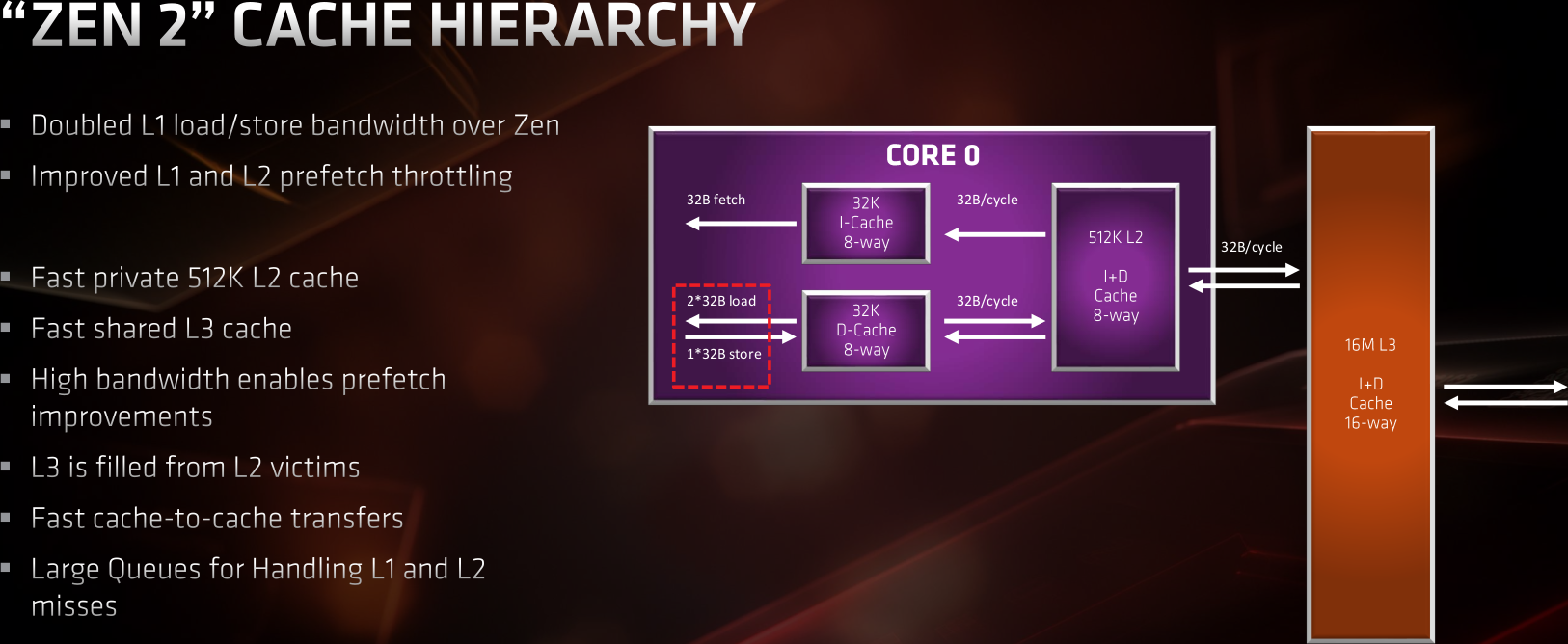
![zen2 archi cache [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-cache-hier_t.png "La magie de la loupe, sans loupe")
Comme vu dans la partie précédente, le débit entre les registres et le L1 est doublé, suivant l'élargissement du pipeline vectoriel, quant au L3, il reste de type victime. Néanmoins, sa promotion en version privée par CCX engendre une latence supplémentaire lors des accès mémoire, puisqu'il faut alors consulter et invalider le cas échéant les lignes de cache d'autres CCX contenant les données recherchées.
![zen2 nouvelles instructions [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-new-instr_t.png "Ultra bouzotron HD max def")
Avec une structure cache qui se complexifie encore un peu plus, il n'est pas surprenant de voir AMD ajouter quelques instructions, afin de donner plus de libertés au programmeur quant à la gestion mémoire. CLWB, déjà présent chez Intel, permet d'écrire la donnée en mémoire alors qu'elle n'est présente que dans un cache. WBNOINVD permet de propager en mémoire toutes les données du cache sans pour autant les évincer et d'autres répartitions seront possibles via des compteurs hardware, ici aussi il s'agit d'un réalignement sur les bleus qui proposent une fonctionnalité similaire sur les gammes serveurs.
![zen2 / spectre V4 correction [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-spectre_t.png "Ne pas appuyer ici")
Qui dit cache et mémoire dit également vulnérabilités, puisque Spectre et Meltdown (et leurs dérivés !) se cachent dans cette infrastructure. AMD étant assez épargné de ces découverts, Zen 2 ne corrige finalement en hard qu'une seule faille : SSB ou Speculative Store Bypass, aussi connu sous le nom de Spectre V4.
![zen2 infinity fabric [cliquer pour agrandir]](/images/stories/articles/cpu/zen2/ryzen_3000/zen2-archi-infinity-fabric_t.png "Visionner en grand sur un magnifique pop-up")
SI l'infinity fabric a été retirée entre CCX, elle reste présente dans ces Zen 2 pour relier entre eux le(s) CCD et le cIOD au travers de sa seconde itération. AMD annonce ainsi avoir retravaillé son design afin d'améliorer son débit, sa consommation et surtout sa latence, en découplant sa fréquence (Fclk) de la fréquence du système mémoire unifié (Uclk), nous verrons ce qu'il en est dans la suite de ce test.
En parlant de suite, rendez-vous page suivante pour en apprendre plus sur son intégration pour les premières moutures grand public.
|
|
| Un poil avant ?Test • AMD RX 5700 XT & RX 5700 | Un peu plus tard ...Bon plan • Le Ryzen 7 3700X à 338,31 € (préco) | |