Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018



Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018
Après avoir détaillé l'architecture et avant de parler plus en détail des fonctionnalités proposées, voyons comment NVIDIA a traduit tout cela en pratique, via la description succincte des différents GPU conçus pour l'occasion. Pour rappel, voici les cartes annoncées durant la Gamescon :
![3 cartes lancées [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/geforce_rtx_t.jpg "Enlarge your pe...icture")
Trois cartes donc. En se référant à l'historique récent, nous étions en droit de penser que le modèle Ti utiliserait le plus gros GPU disponible en version légèrement castrée (quelques SM désactivés et éventuellement un contrôleur mémoire) et que les 2 autres partageraient un autre GPU, plus petit, dans des variantes légèrement différentes au niveau des éléments actifs là-aussi. En fait, ce n'est pas tout à fait cela, comme nous allons le voir dans le tableau ci-dessous. Nous avons également ajouté la précédente génération à titre de comparaison.
| Cartes | GPU | Nombre de transistors | Superficie Die |
|---|---|---|---|
| GeForce RTX 2080 Ti | TU102 | 18,6 Milliards | 754 mm² |
| GeForce RTX 2080 | TU104 | 13,6 Milliards | 545 mm² |
| GeForce RTX 2070 | TU106 | 10,8 Milliards | 445 mm² |
| GeForce GTX 1080 Ti | GP102 | 12 Milliards | 471 mm² |
| GeForce GTX 1080 | GP104 | 7,2 Milliards | 314 mm² |
| GeForce GTX 1070 | GP104 | 7.2 Milliards | 314 mm² |
Ainsi, la plus petite des 3 cartes lancées n'utilise pas la puce TU104 dans une version bridée comme on pouvait s'y attendre, mais un TU106, que l'on imaginait davantage dévolu à une hypothétique RTX 2060. Pourquoi diable le caméléon a-t-il procédé de la sorte ? Tout n'est que supputation, mais un rapide coup d’œil à la taille des différents die, donne un élément de réponse. La plus grosse puce gaming de la série 10 et utilisée sur le flagship, ne dépasse que d'un peu moins de 6% (en superficie) TU106...
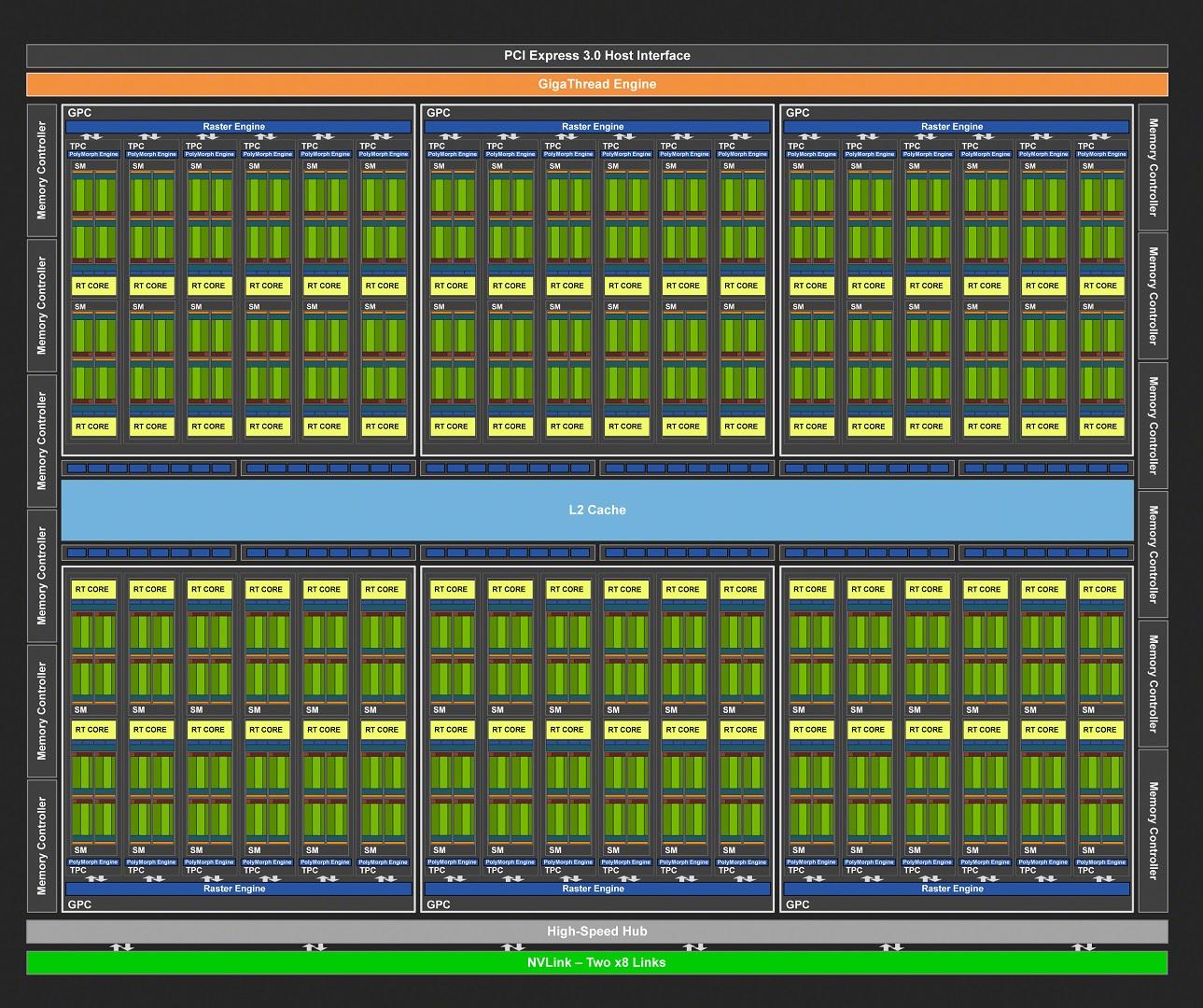
Tout cela démontre s'il le fallait encore, que les GPU Turing nécessitent de nombreux transistors pour ajouter les capacités en Ray Tracing et IA, cela se paie donc au niveau de la taille des die, le procédé de gravure retenu ne permettant pas d'améliorer la densité de ces derniers. Et que dire de TU102 qui utilise un die 60% plus grand que GP102 ? Nous n'allons pas le décrire à nouveau en intégralité ici, puisque nous l'avons déjà fait page 2, mais nous intéresser à la déclinaison utilisée au sein de la RTX 2080 Ti.
![Diagramme TU102 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tu102_diagram_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Vu les coûts de production d'un telle puce, elle ne sera disponible en version intégrale que sur les Quadro RTX 6000/8000 (6 300$ /10 000$ avec 24 / 48 Go de GDDR6) pour le moment (une éventuelle TITAN T à l'avenir ?). Les puces partiellement fonctionnelles, permettront d'augmenter le taux d'usage et réduire ainsi les coûts. C'est donc une puce dont 4 SM et un contrôleur mémoire 32-bit ont été désactivés, qui est utilisée. Du dernier point cité, découle la désactivation automatique de 8 ROP et 512 Ko de cache L2. Au final, voici les caractéristiques principales de cette variante de TU102, résumées dans le tableau ci-dessous.
| GeForce RTX 2080 Ti | Quantité activée |
|---|---|
| GPC | 6 |
| TPC / SM | 34 / 68 |
| CUDA Cores | 4352 |
| TMU | 272 |
| Tensor Cores | 544 |
| RT Cores | 68 |
| ROP | 88 |
| L2 (Mo) | 5,5 |
| Bus mémoire (bits) | 352 |
Intéressons-nous à présent à TU104, qui prend place au sein de la RTX 2080. Première constatation, il n'est pas composé de 4 GPC comme c'est traditionnellement le cas sur cette gamme de GPU, mais de 6 à l'instar des GP102/TU102. Il gagne ainsi 2 Raster Engine, de quoi afficher jusqu'à 6 triangles par cycle. Il a toutefois subit une cure d'amincissement, puisque chaque GPC ne contient plus "que" 4 TPC / 8 SM, soit 33% de moins que son grand frère. Il en est de même pour les contrôleurs mémoire, ROP et cache L2. Du côté comptable, le GPU embarque un bus mémoire à 256-bit, 64 ROP, 48 SM et donc 3072 CUDA Cores, 192 TMU, 384 Tensor Cores et 48 RT Cores. Pour finir, il ne conserve qu'un seul lien 8x NVLink sur les 2 du TU102.
![Diagramme TU104 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tu104_diagram_t.jpg "Même pas cap' de cliquer")
À l'instar de la gamme supérieure, le GPU utilisé est quelque peu bridé, avec un TPC inactif soit 46 SM activés. Le bus mémoire et les éléments liés (ROP et L2) sont par contre conservés intégralement. Ci-dessous, le récapitulatif du GPU dans cette configuration.
| GeForce RTX 2080 | Quantité activée |
|---|---|
| GPC | 6 |
| TPC / SM | 23 / 46 |
| CUDA Cores | 2944 |
| TMU | 184 |
| Tensor Cores | 368 |
| RT Cores | 46 |
| ROP | 64 |
| L2 (Mo) | 4 |
| Bus mémoire (bits) | 256 |
Finissons par la surprise de ce lancement, alias TU106 qui se retrouve au sein de la RTX 2070. Il s'appuie cette fois sur 3 GPC, réduisant d'autant les unités de rastérisation, mais reprenant la constitution de ceux utilisés par TU102, soit 6 TPC / 12 SM. On peut donc voir TU106 comme un demi TU102, à l'interface mémoire près. En effet, alors que le caméléon utilise un bus mémoire 192-bit sur ses séries x06 depuis plusieurs années, ce sont cette fois pas moins de 8 contrôleurs mémoire qui prennent place au sein du die, pour une largeur cumulée de 256-bit, la même que TU104. Il en va de même pour les éléments liés, c'est-à-dire les 64 ROP et 4 Mo de cache L2.
![Diagramme TU106 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tu106_diagram_t.jpg "Ne pas appuyer ici")
Le GPU utilisé sur la GeForce RTX 2070 est par contre complet cette fois, vous pouvez donc retrouver ses caractéristiques principales dans le tableau ci-dessous.
| GeForce RTX 2070 | Quantité activée |
|---|---|
| GPC | 3 |
| TPC / SM | 18 / 36 |
| CUDA Cores | 2304 |
| TMU | 144 |
| Tensor Cores | 288 |
| RT Cores | 36 |
| ROP | 64 |
| L2 (Mo) | 4 |
| Bus mémoire (bits) | 256 |
Voilà pour la mise en œuvre pratique de Turing, en parlant chiffres, la RTX 2070 est-elle vraiment pénalisée par rapport à sa devancière de cette "rétrogradation" sur un GPU différent ? Il faudra attendre les tests pour s'en assurer, toutefois, 37% (calcul) et 25 % (bande passante mémoire) séparaient 1080 et 1070. Si l'on s'attache cette fois aux écarts séparant 2080 et 2070, ils sont de respectivement 35% et 0%. Difficile donc de crier au scandale, sauf pour les amateurs de multi-GPU. Voilà pour notre tour d'horizon de l'architecture Turing, intéressons-nous page suivante aux nouvelles fonctionnalités misent en œuvre avec cette dernière.
|
|
| Un poil avant ?Live Twitch • Démo de Forza Horizon 4 sur PC | Un peu plus tard ...Lara benchée par tous les... GPU bien sûr ! | |
| 1 • Préambule |
| 2 • Turing, une architecture qui évolue |
| 3 • RT Cores / Tensor Cores / Rendu hybride |
| 4 • |
| 5 • Les nouvelles fonctionnalités |
| 6 • VR, Vidéo & Encodage / NV Scanner / SLi |
| 7 • Conclusion |