Preview • Turing : la révolution Ray Tracing & IA ? |
• 14 Septembre 2018



Preview • Turing : la révolution Ray Tracing & IA ? |
• 14 Septembre 2018
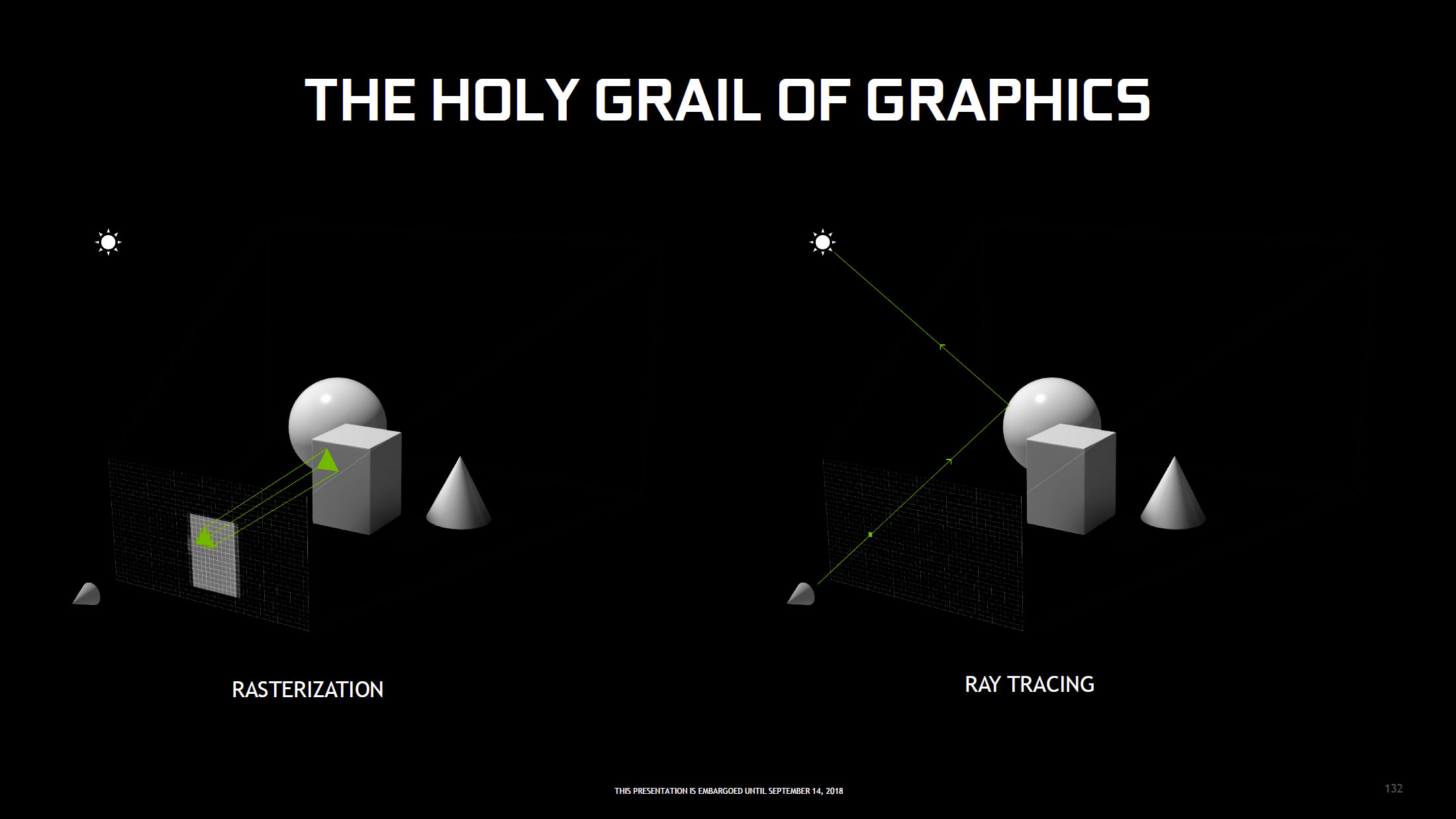
Nous venons de le voir, l'architecture Turing repose toujours sur une base axée rastérisation pour générer les images 3D et les afficher sur nos écrans. Cette dernière consiste à projeter une image vectorielle (composée de triangles) en 3 dimensions, vers une image à 2 dimensions constituées de pixels. Pour ce faire, il est nécessaire de calculer à partir des sommets des triangles (vertices), les positions et couleurs de chaque pixel affiché à l'écran. C'est ce principe de base qui est représenté à gauche sur l'image ci-dessous.
Bien entendu, de nombreuses autres étapes sont mises en œuvre pour obtenir un rendu plus réaliste, comme par exemple appliquer des textures, lisser les arrêtes, calculer des éclairages, réflexions, etc., modifiant les valeurs et intensités des couleurs. Toutefois, chaque ajout complexifie les calculs et nécessite d'être prévu par le programmeur (ou géré nativement par le moteur 3D). L'avantage de la rastérisation, est la rapidité de traitement, en particulier la détermination des pixels à afficher via Z-Buffer (tampon stockant les coordonnées z (profondeur) de chaque pixel), la rendant compatible avec la 3D "temps réel" de nos jeux vidéo.
![Principe Rastérisation et Ray Tracing [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/raster_vs_rt_t.jpg "Enlarge your pe...icture")
Mais il existe une autre technique populaire pour rendre des images 3D : le lancer de rayons ou Ray Tracing (davantage usité) en anglais. Son fonctionnement est quelque peu inversé (schéma de droite ci-dessus), puisque cette fois, il ne s'agit pas de convertir une image vectorielle en matricielle, mais de reconstituer une image virtuelle en suivant depuis la vue utilisateur, le cheminement des rayons qui traversent le plan 2D de l'image jusqu'aux sources lumineuses, en prenant en compte les principes optiques de réflexions, réfractions ou blocage (conduisant aux ombres) de la lumière. L'avantage est d'obtenir un résultat pouvant être photo-réaliste, expliquant son adoption massive dans le cinéma. La contrepartie est une somme de calculs colossale, ce qui n'est pas forcément handicapant pour un rendu destiné à être inclus dans un film en post-production (pré-calculé), mais prohibitif pour une exécution en temps réel dans un jeu vidéo...
Turing progresse face à Pascal en termes de puissance de calcul brute "traditionnelle", mais reste (très) loin du compte à ce niveau, pour espérer réaliser du Ray Tracing intégral en temps réel sur des scènes complexes. Il fallait donc pour le caméléon résoudre une problématique tout sauf simple : comment proposer les avantages qualitatifs du lancer de rayons, tout en répondant aux exigences de vitesse d'un jeu vidéo ? La réponse apportée est pour le moins originale, mais pragmatique : un rendu hybride, conservant une base rastérisation là où cette dernière reste pertinente (Z-buffer, etc.), mais en utilisant le Ray Tracing pour les tâches qui donneront de meilleurs résultats avec cette technique (éclairage, réflexion, etc.). Bien sûr, rien n'empêche de réaliser l'intégralité de la scène avec l'une ou l'autre technique, mais avec la plupart des compromis usuels de ces dernières (qualité ou performance).
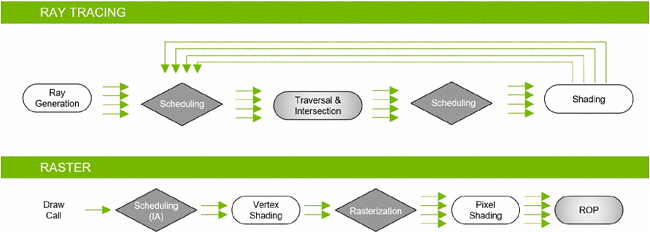
Les pipelines de rendu dédiés aux 2 méthodes peuvent travailler de concert, ce qui est à la base du rendu hybride, nous détaillerons quelque peu cette notion en bas de page. La somme de calculs à réaliser en Ray Tracing est étroitement liée à la complexité de la scène (définition, nombre d'objets, etc.), mais aussi à la qualité de rendu souhaité. Cette dernière dépend en grande partie du nombre de rayons diffusés par pixel. NVIDIA s'est donc attelé à en limiter le nombre tout en préservant la qualité visuelle. Il use pour cela de nombreux filtres de "débruitage" (denoising), s'appuyant sur des algorithmes faisant usage ou non de l'IA, selon leur efficacité. Le caméléon précise que ces derniers sont régulièrement mis en concurrence avec des évolutions de ceux s'appuyant sur l'IA (à mesure des progrès de l'apprentissage dans ce domaine), il s'attend à ce que ceux-ci les remplacent progressivement. Toujours est-il qu'ils permettent d'améliorer significativement une image, tout en conservant un nombre de rayons compatible avec l'exécution en temps réel.

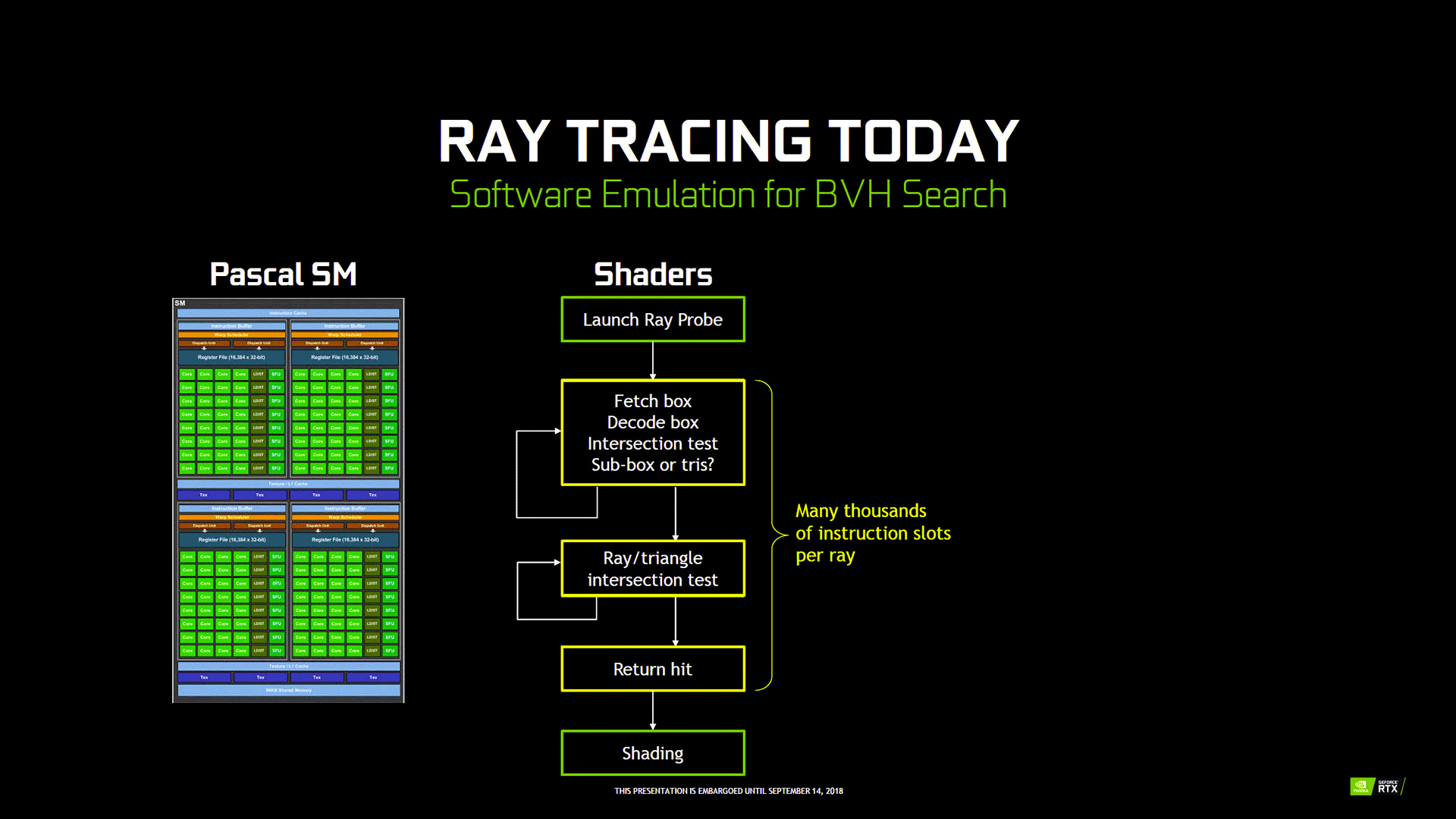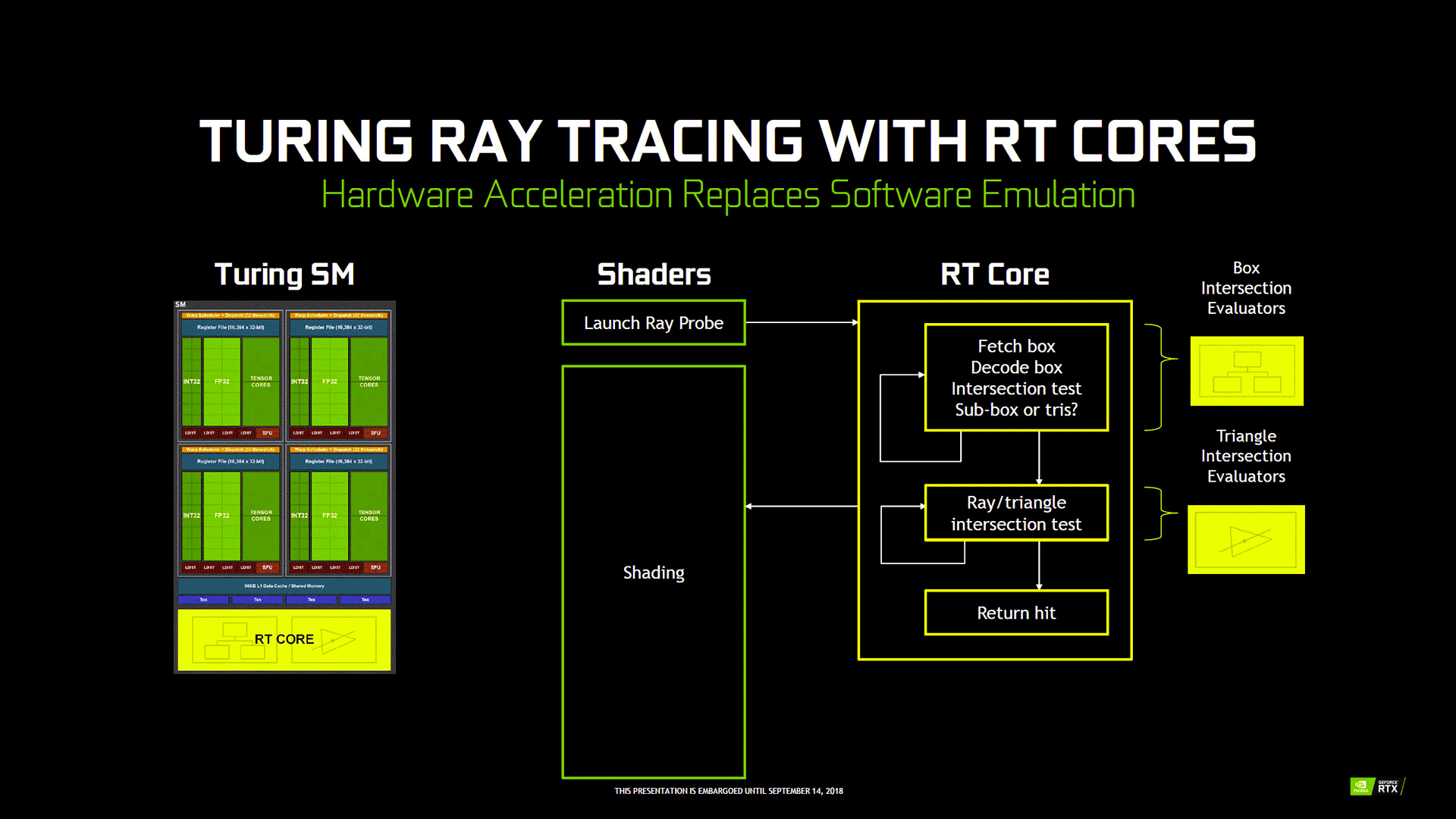
Un autre axe de réduction du nombre de calculs, est l'utilisation de la technique Bounding Volume Hierarchy ou BVH. Kesako ? En fait, une part importante de ces derniers est dédiée à "trouver" le triangle "élémentaire" (des objets 3D) frappé par un rayon, afin de déterminer la trajectoire de ce dernier. C'est là qu'intervient ce fameux BVH. En pratique, cet algorithme teste si le rayon touche une "grande" boite de forme géométrique simple (les tests d'intersections sont ainsi "aisés" à réaliser) qui englobe l'objet ou une partie de ce dernier. Si ce n'est pas le cas, il passe à une autre grande boite, si par contre le rayon touche la boite, il effectue une recherche plus fine à l'intérieur de cette dernière via des boites plus petites et ainsi de suite jusqu'à isoler le triangle d'intersection.
![Bounding Volume Hierarchy [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/bvh_t.gif "3N C11QU4N7 C357 P1U5 6r4ND")
Les RT Core entrent alors en scène : leur objectif est de fournir une accélération matérielle au BVH. NVIDIA aurait (notez le conditionnel, car il reste très discret sur le sujet, constituant un avantage stratégique sur la concurrence) à priori choisi l'option d'un circuit spécialisé (ASIC), pour des raisons de coût en transistors, mais surtout de performance, par rapport à une exécution purement logicielle de l'algorithme sur une unité de calcul "plus générique". En effet, d'après le caméléon, sur une architecture ne disposant pas de circuit spécialisé, ces opérations coûteraient des milliers de cycles d'instructions supplémentaires par rayon. En définitive, la RTX 2080 Ti serait 10 fois plus rapide que la GTX 1080 Ti, lors de l'exécution d'un rendu en Ray Tracing intégral.
![Les apports de Turing pour le Ray Tracing [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/ray_tracing-pascal_vs_turing_t.gif "Visionner en grand sur un magnifique pop-up")
Voilà ce que nous pouvions vous dire sur le Ray Tracing tel qu'implémenté au sein de l'architecture Turing du caméléon, mais aussi des unités dédiées RT Cores, qui rendent possible sa mise en œuvre pour les jeux, au sein des nouveaux GPU des verts. Il est important de noter que Microsoft a annoncé au printemps son API DXR, pour DirectX Raytracing (disponible pour le moment uniquement en mode développeur avec Windows 10 1803, mais sera disponible pour tous avec la version 1809 aka October Update). Cette dernière devrait favoriser l'émergence de cette technologie, à l'instar du portage des instructions RTX au sein de Vulkan par NVIDIA. Il est temps de passer à la seconde grosse nouveauté de l'architecture (par rapport à Pascal), les Tensor Cores.
Depuis quelques années, l'intelligence artificielle est revenue à la mode, en particulier avec l'adoption des GPU pour les opérations de Machine Learning. Il n'est pas question ici de vous assommer avec les principes de fonctionnement relativement complexes de ces activités, tout au plus nous contenterons-nous de rappeler, qu'il s'agit de techniques d'apprentissage réalisées le plus souvent via des réseaux de neurones artificiels, simulés par les unités de calcul. NVIDIA, qui a su s'imposer ses dernières années comme l'indiscutable pourvoyeur de matériel sur le sujet, tant par ses GPU que son écosystème logiciel dédié, y voit une utilité pour faire progresser significativement les usages ludiques. Il évoque ainsi une intelligence accrue des PNJ, mais aussi une détection des tricheurs, voir une amélioration des graphismes. Nous reviendrons plus en détail sur ce dernier point page suivante.
![Deep Learning [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/deep_learning_t.jpg "Ne pas appuyer ici")
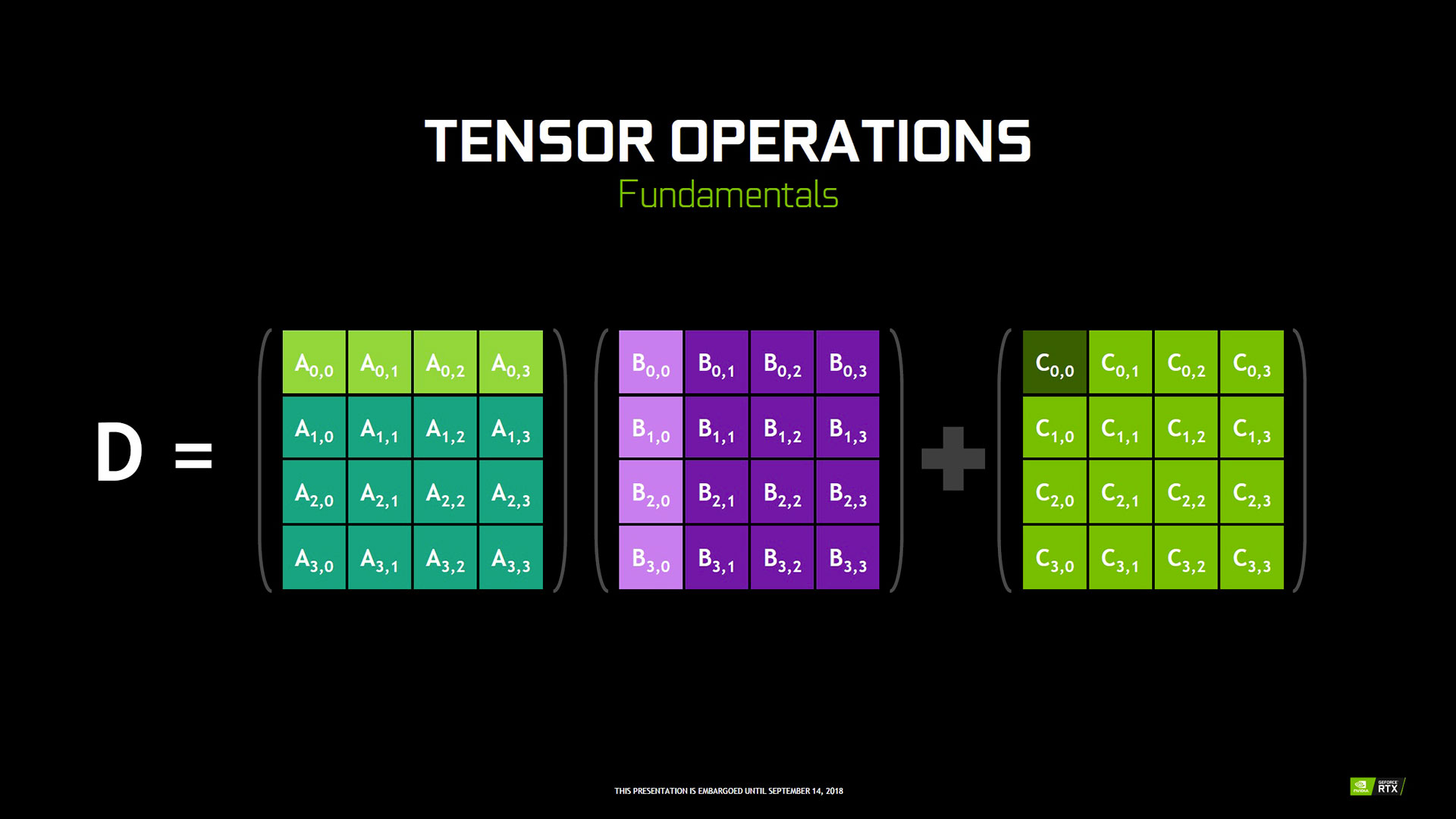
Avec Volta, NVIDIA a introduit dans ses GPU des unités spécialisées pour les opérations d'IA, les Tensor Cores. Comme leur nom l'indique, elles sont destinées à opérer des objets mathématiques nommés Tenseurs. D'un point de vue moins abstrait, elles sont spécialisées dans les calculs entre matrices, en particulier la réalisation d'un produit puis d'une somme. Ainsi, un seul Tensor Core est capable d’exécuter l'équivalent de 64 FMA (Fused Muliply-Add) par cycle d'horloge en FP16.
![Opérations de base sur Tenseurs [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/ope_tenseurs_t.jpg "Cliquédélique !")
Ce chiffre est doublé, voir quadruplé si on utilise des données d'entrée à précision réduite (INT8/INT4). Ces niveaux de précision très faibles ont un intérêt spécifique, dans le cadre de l'inférence (nous décrirons cette dernière un peu plus loin). Une vitesse de traitement accrue de ces derniers est donc bienvenue et a une utilité pratique dans le domaine IA.
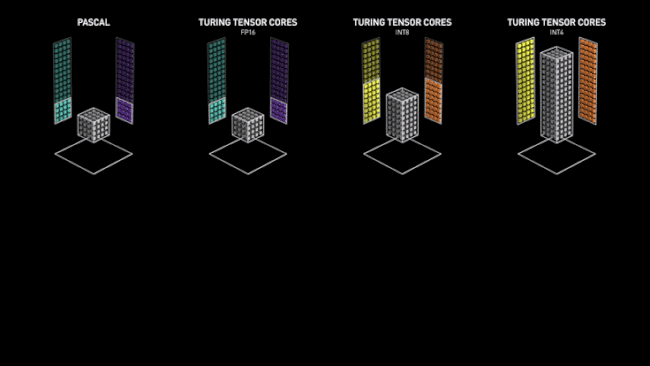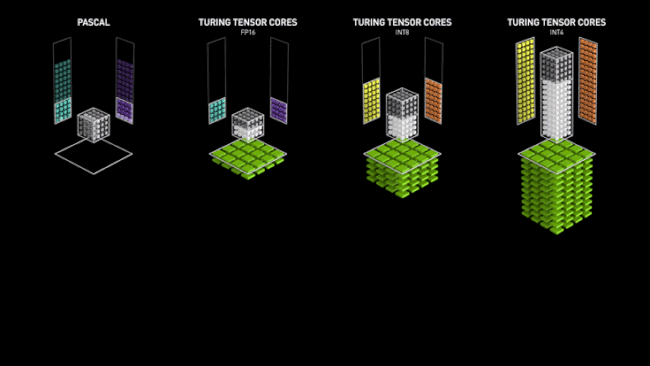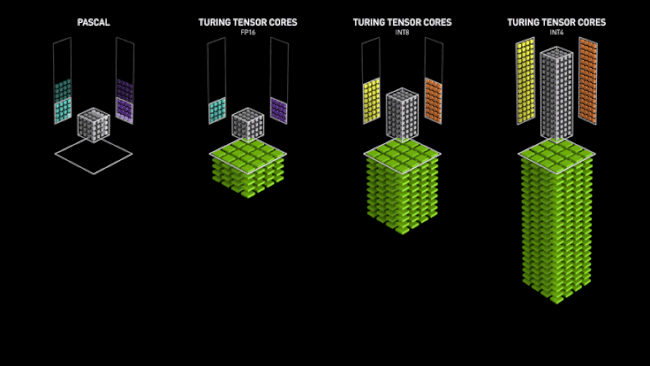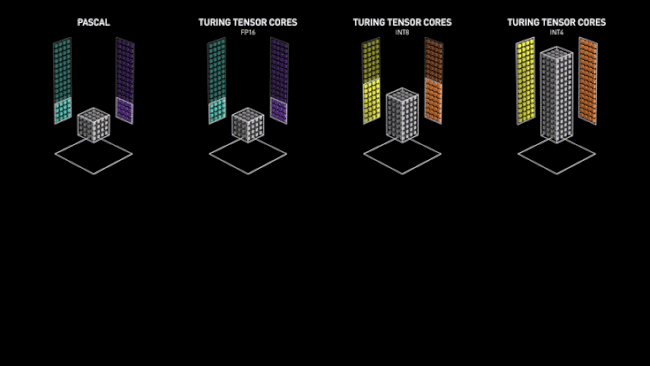
Le caméléon a donc conçu ces unités vectorielles capables de paralléliser au maximum ce type d'opérations et ainsi obtenir des performances largement supérieures à celles obtenues via des ALU plus "traditionnelles", pour ces tâches. C'est là aussi une sorte de retour en arrière pré-G80, qui avait signé l'abandon relatif du vectoriel au profit du scalaire. Reste que pour cet usage précis, le choix est logique, les vérités d'un jour n'étant pas forcément celles du lendemain, du fait de l'évolution constante des besoins. Ci-dessous, une petite animation sur les Tensor Cores, imaginée par NVIDIA pour décrire leur fonctionnement (lors du lancement de Volta) en comparaison d'unités plus traditionnelles (Pascal). Elle reste toutefois valable pour Turing (cf. image au-dessous).
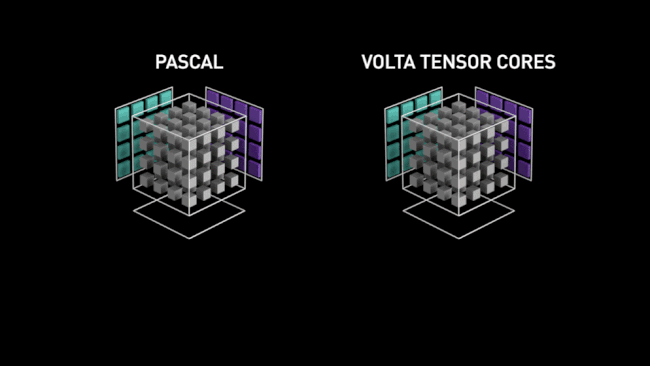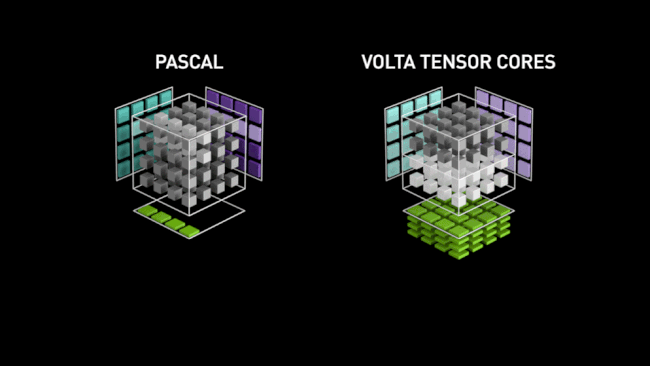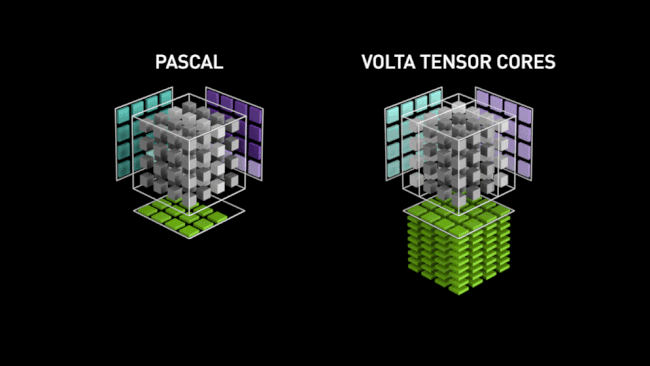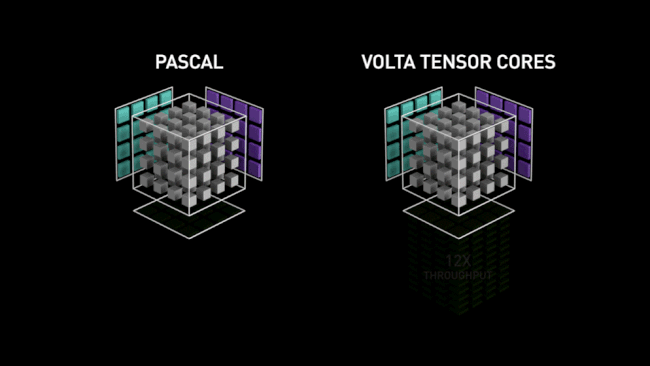
![tensor cores t [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tensor_cores_t.jpg "Ne pas appuyer ici")
Augmenter significativement la capacité du GPU à produire ce type de calculs (y compris avec des précisions faibles), c'est bien beau, mais pour quel usage pratique ? Le traitement d'images est par exemple un des domaines où l'IA a réalisé les plus gros progrès en termes de classification (par exemple, décider parmi des choix fixes le thème d'une image ou détecter la présence d'un individu). Il est également possible de réaliser de la prédiction, par exemple d'upscaler une définition avec un résultat très performant ou de retirer des artefacts présents sur une image - voire une vidéo -.
Pour cela, il faut par contre entraîner un réseau neuronal sur ce type d'usage spécifiquement (cela reste encore mécompris, mais le réseau doit par exemple apprendre par lui-même à calculer le vecteur de déplacement des pixels interpolés), ce qui nécessite une puissance de calcul bien au-delà d'une simple carte graphique. Pour le joueur, l'utilisation principale sera l'inférence : l'utilisation de ce réseau pré-entraîné pour réaliser ces prédictions, rendue possible en temps réel via l'accélération fournie par les Tensors Cores. Le résultat atteint est déjà visuellement supérieur à ceux obtenus via des algorithmes existants pour ces usages, mais ne faisant pas appel à l'IA, l’inconvénient résidant dans une vision plus restreinte du but des opérations réalisées par l'algorithme.
La même approche est utilisée pour générer des ralentis sur des flux vidéos (ajouter des images intermédiaires au sein d'un flux existant). Enfin, grâce à InPainting, il est possible par exemple de retirer une zone d'une image (NVIDIA cite par exemple des lignes électriques) et remplacer la partie vide par d'autres éléments de contexte (dans ce cas là un fond de ciel correspondant). Cette fonctionnalité n'a rien de bien nouveau (notre profanateur préféré Matthieu s'en délecte régulièrement), mais alors qu'elle s'appuie sur des mécanismes de copie de données de l'image existante, pouvant du coup générer des artefacts visuels, l'algorithme InPainting utilise son apprentissage sur de nombreuses images existantes, pour reconstituer les parties manquantes. De quoi imaginer des profanations de comptoir encore plus réalistes et donc méchantes ?
![Usage IA [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/usage_ai_t.gif "Même pas cap' de cliquer")
Nous en avons fini avec cette courte introduction aux Tensors Cores et à l'utilité de l'intelligence artificielle dans des domaines variés. Ce point sera illustré page 5, avec la description d'une mise en œuvre pratique de ces fonctionnalités par NVIDIA, dans un cadre vidéo-ludique. Terminons notre tour d'horizon de l'architecture, par un focus sur le rendu hybride selon le géant vert.
Turing est en définitive une architecture très polyvalente, puisque capable de calculer des images en rastérisation et/ou Ray Tracing, mais aussi accélérer des tâches d'IA. Pour pouvoir en tirer profit de manière optimale, il est nécessaire de réaliser un certain nombre de tâches de manière concomitante, afin que le temps de rendu total d'une image, reste compatible avec son usage dans une activité en temps réel. NVIDIA précise à ce sujet, que sa dernière architecture est bel et bien capable d'accéder à certaines de ses ressources, de manière simultanée. On imagine dès lors que le caméléon a prévu des processeurs de commande très évolués, capable de mixer les files de calculs et rendus efficacement.
![Exemple [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/modele_rendu_image_turing_t.gif "Cliquédélique !")
Le caméléon en profite pour donner un exemple de rendu "typique" d'une image, faisant appel aux différentes unités constitutives du GPU de la GTX 2080 Ti. Il introduit également un indice de performance des cartes, en appliquant un ratio d'utilisation de chaque ressource (basé sur la valeur brute maximale de ces dernières). Nous restons toutefois pour le moins dubitatifs, quant à la pertinence d'un tel indice, la charge pouvant varier largement d'un jeu à l'autre (et même au sein d'un même jeu), sans compter que l'on mélange pour le coup, des choux et des carottes (TFLOPS, TIPS, RTOPS, etc.).
Il s'agit davantage ici d'un mode de communication marketing, que d'un indice représentatif selon nous, probablement pour insister sur le fait que ces cartes ne se limitent pas à leur puissance de calcul en FP32 (ce qui est vrai), valeur qui n'explose d'ailleurs pas entre génération. De là à penser que cela ennuyait quelque peu NVIDIA... Il n'en reste pas moins que la polyvalence de l'architecture permet de mixer les techniques comme illustré ci-dessous, et pourra s'avérer redoutable selon l'usage qu'en feront les développeurs - et sous couvert qu'il n'y ait pas de goulot d'étranglement / limitation, grippant cette belle mécanique -.
![Exemple de rendus hybrides [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/rendu_hybride_t.jpg "La magie de la loupe, sans loupe")
Voilà ce que nous pouvions vous dire sur l'architecture Turing, voyons page suivante les puces que le caméléon a conçues pour mettre en pratique cette dernière.
|
|
| Un poil avant ?Live Twitch • Démo de Forza Horizon 4 sur PC | Un peu plus tard ...Lara benchée par tous les... GPU bien sûr ! | |
| 1 • Préambule |
| 2 • Turing, une architecture qui évolue |
| 3 • |
| 4 • 3 cartes = 3 GPU |
| 5 • Les nouvelles fonctionnalités |
| 6 • VR, Vidéo & Encodage / NV Scanner / SLi |
| 7 • Conclusion |