Test • GeForce GTX 970 & 980 |
• 19 Septembre 2014


Test • GeForce GTX 970 & 980 |
• 19 Septembre 2014
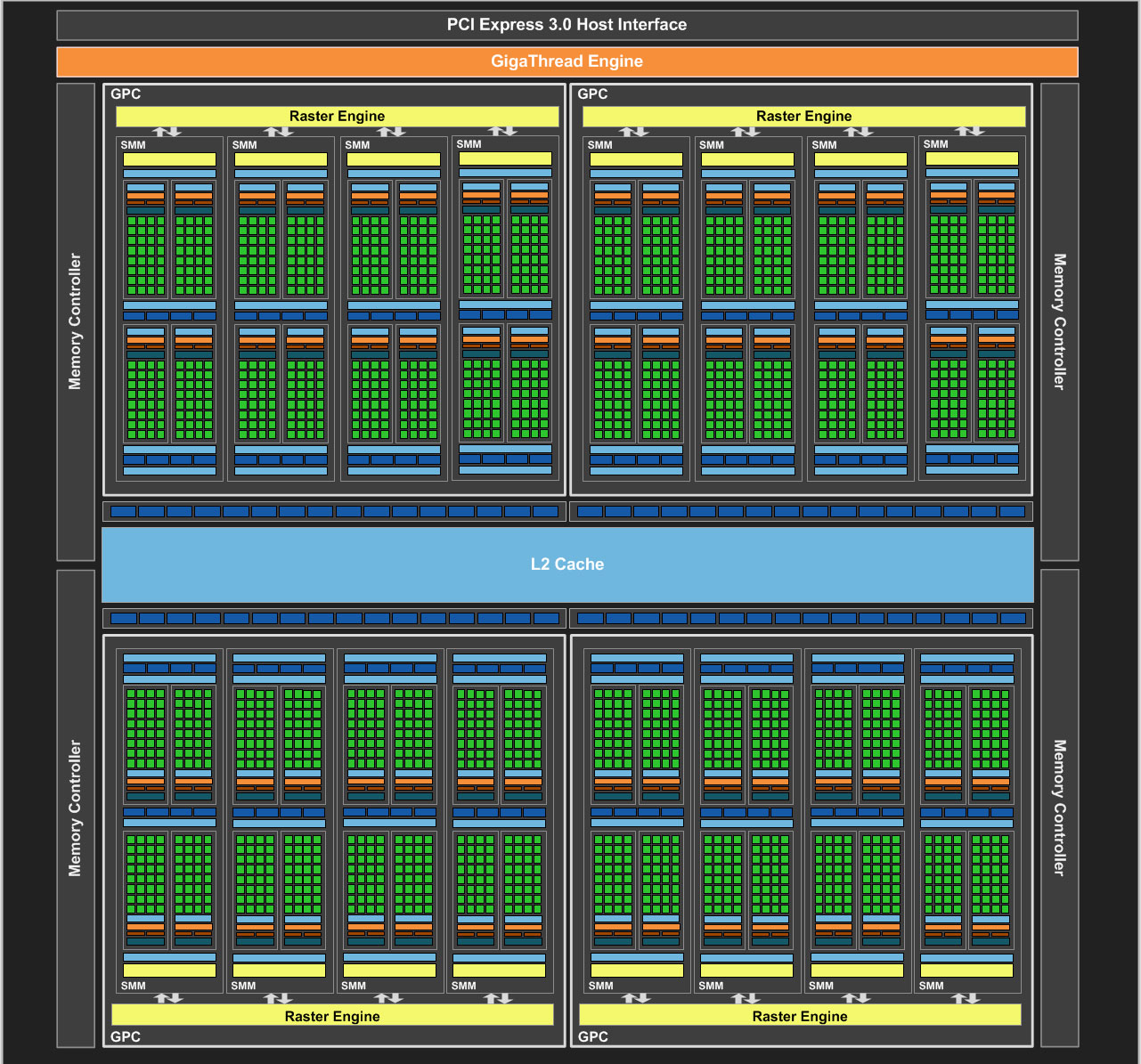
Pour concevoir son nouveau GPU, NVIDIA s'appuie donc sur sa dernière architecture Maxwell, retouchée pour l'occasion par rapport à la version étrennée par la 750 Ti. Elle succède à Kepler, elle-même fortement basée sur Fermi qui a posé les fondations des puces modernes du caméléon. Ainsi, le GM204 s'appuie toujours sur des unités polyvalentes nommées Streaming Multiprocessor ou SM pour les intimes. Nous reviendrons plus en détails sur ces derniers puisque c'est en leur sein que se trouve une grande partie des évolutions de l'architecture, mais commençons avant cela par le diagramme GPU d'un point de vue macroscopique :
![Diagramme GM204 [cliquer pour agrandir]](/images/stories/articles/gpu/gtx_980_970/images/diagramme_gpu_t.jpg "Enlarge your pe...icture")
Diagramme logique du GM204 - Cliquer pour agrandir
Ces SMM (le second M signifiant Maxwell) sont regroupés au sein des GPC (Graphics Processor Cluster) qui intègrent également un Raster Engine ou moteur de rastérisation, chargé de découper les triangles (toujours 4 par cycle) en provenance des unités géométriques des SM en pixels avant de les renvoyer vers les unités de calcul de ces mêmes SM. Sur GK104, chaque GPC (4 en tout) contenait uniquement 2 Streaming Multiprocessor nommés SMX sur Kepler, pour un total de 8. Avec Maxwell, ce sont pas moins de 4 SMM qui s'entassent par GPC toujours au nombre de 4. Faites les comptes, on passe donc de 8 SMX au double, avec pas moins de 16 SMM pour les puces de même gamme (xx4). Toutefois, ces Streaming Processor ne sont pas identiques comme nous le verrons bientôt, mais avant cela, jetons un coup d'oeil au sous-système mémoire.
Le bus mémoire reste inchangé à 256-bit puisque toujours constitué de 4 contrôleurs 64-bit MAJ : "l'affaire" GTX 970 révèle qu'en fait le bus mémoire est composé de 8 contrôleurs 32-bit contrairement à la représentation schématique fournie par NVIDIA, le cache L2 associé à chacun d'entre-eux est par contre quadruplé, passant ainsi de 128 Ko sur GK104 à 512 Ko 256 Ko par contrôleur 32-bit avec GM204, soit un total de 2 Mo pour le GPU. Qui plus est, NVIDIA indique avoir travaillé ses divers algorithmes de compression (sans perte) des couleurs afin de réduire les besoins en bande passante mémoire. Parmi ceux-ci, le caméléon évoque la technique Delta Color qui permet de calculer l'écart entre 2 couleurs sur des pixels adjacents plutôt que de coder indépendamment chaque couleur de pixel, ce qui peut être très bénéfique si les couleurs sont proches. Ces algorithmes implémentés depuis Fermi, en sont donc à leur troisième révision qui permet de proposer davantage de choix de calculs Delta au "compresseur". AMD vient justement de communiquer sur le sujet en expliquant que l'amputation du bus mémoire avec le passage de Tahiti (384-bit) à Tonga (256-bit) sur la R9 285 par rapport à la R9 280, était compensée en partie par ce biais...
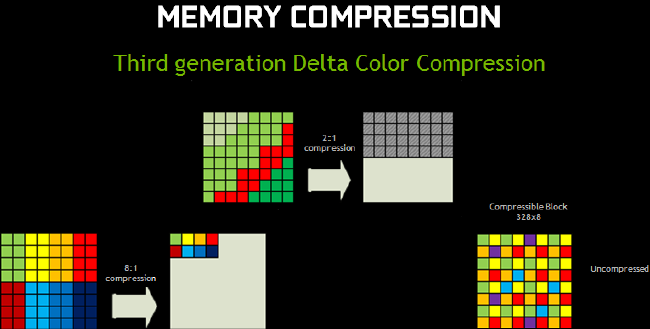
Exemples d'algoritmes de compression couleur
Au final, entre l'accroissement du cache L2 et les divers algorithmes de compression couleur, NVIDIA annonce un besoin en bande passante mémoire en baisse de 25% en passant de Kepler à Maxwell. Avant d'attaquer en détail l'évolution des SM, un dernier mot pour préciser que malgré la conservation du bus mémoire à 256-bit, le nombre de ROP (vous savez, les petites bêtes chargées d'écrire en mémoire) a de son côté été doublé pour atteindre 64 soit 33% de plus que sur GK110 et autant que les puces Hawaii d'AMD pourtant équipées d'un bus 512-bit. Comme le caméléon n'a pas fait les choses à moitié, les moteurs de rastérisation ont suivi l'inflation du nombre de SM et sont donc capables de générer 16 pixels par cycle (contre 8 auparavant), soit là-aussi 64 en tout pour les 4 GPC. Cette valeur peut être soutenue sur un GM204 complet car les SMM sont de leur côté capables de traiter 4 pixels 32-bit par cycle et donc là-aussi 64 en tout puisqu'ils sont 16. De quoi proposer un fillrate, traditionnel point faible des GeFORCE face aux RADEON, doublé et particulièrement utile avec des définitions toujours plus élevées. Voyons à présent ce qu'ils ont dans le ventre ces fameux SMM :
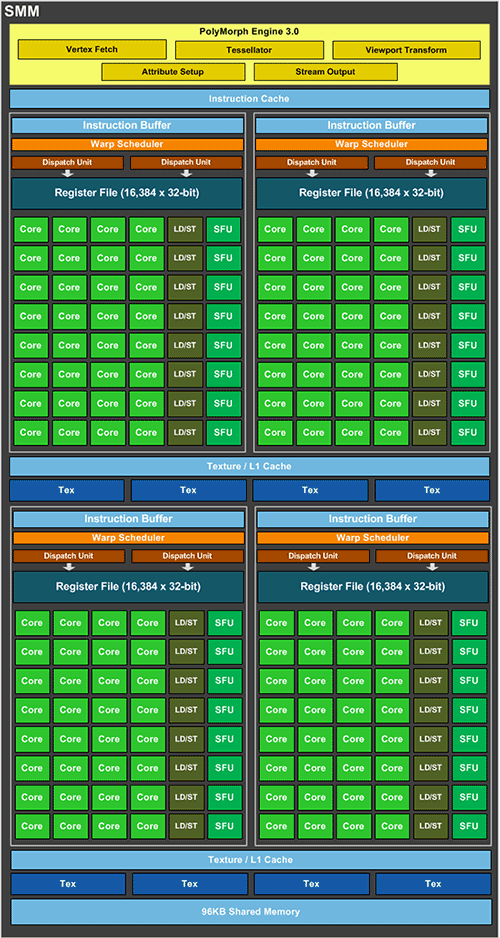
Un SMM, au coeur de Maxwell
Afin de doubler le nombre de SM au sein du GPU sans pour autant doubler le nombre de transistors nécessaires, NVIDIA a du revoir sérieusement leur composition façon diète. Le nombre d'unités de calcul scalaires (abusivement nommées Core par le marketing) passe ainsi de 192 pour un SMX (Kepler) à 128 pour un SMM. Toutefois, cela n'a pas pour conséquence une perte sèche de 33% de la puissance de calcul de ces derniers par rapport à leurs devanciers comme on pourrait le penser en premier lieu : ces "Cores" sont en fait exploités au sein du SM par groupe de 32 créant ainsi des unités vectorielles SMID. Avec 192 "Cores" on en obtient donc 6, pour autant chaque SMX ne disposait que de 4 ordonnanceurs (scheduler) soit 2 de moins, conduisant en pratique à une sous exploitation de ces unités SMID qui se "tournaient fréquement les pouces" en attendant l'attribution de calculs à réaliser. NVIDIA a donc fait le ménage pour aligner ces 2 valeurs (suppression de 2 SMID) ce qui augmente mécaniquement l'efficacité d'un SMM qui peut exploiter de manière optimale toutes ces unités de calcul cette fois. Autre régime sévère, les TMU ou unités de texturing qui sont de par leur conception très gourmandes, passent de 16 à 8 avec Maxwell, l'évolution des moteurs 3D déplaçant le besoin en faveur du calcul par rapport au texturing devrait limiter l'impact de cet arbitrage.
La gestion des calculs en double précision (DP soit 64-bit) est très limitée (1/32 du débit en SP ou simple précision), ce point n'ayant toutefois aucune incidence pour le rendu 3D, cible du GM204. La hiérarchie mémoire au sein du SMM évolue aussi, ainsi, des 64 ko communs entre le cache L1 et la mémoire partagée sur SMX, on passe à 96 ko intégralement dédiés à cette dernière puisque le L1 est déplacé vers le cache Texture doublé pour l'occasion (12 => 24 Ko) sur SMM. Le Polymorph Engine qui gère la géométrie est toujours présent mais passe en version 3.0 avec des gains annoncés jusqu'à 50% par rapport à la précédente version dans les cas d'utilisation sévère de la Tesselation, sans oublier que le nombre de SMM étant doublé, les Polymorph Engine le sont aussi. En tenant compte de ce même point, les unités de calcul passent donc de 1536 sur GK104 à 2048 sur GM204, quant aux TMU, elles restent donc cantonnées à 128. Tout cela nous donne un joli bébé de 5.2 Milliards de transistors pour 398 mm² gravé en 28nm. Le GK104 se contentait lui de 3.54 Milliards et 294 mm² même si on reste très loin des 569 mm² et 7.1 Milliards de transistors de GK110. Face à la concurrence, la superficie de puce la situe entre Tonga (5 Milliards de transistors / 368 mm²) et Hawaii (6.2 Milliards pour 438 mm²).

Il est beau mon GM104 !
Passons à présent aux diverses nouveautés apportées par cette génération 2 de Maxwell en page suivante.
|
|
| Un poil avant ?Samsung lance un écran 27" FullHD incurvé | Un peu plus tard ...Go-go-gadget au boîtier chez BitFenix avec le Pandora | |





















