Test • AMD Ryzen R3 2200G / R5 2400G |
• 12 Février 2018



Test • AMD Ryzen R3 2200G / R5 2400G |
• 12 Février 2018
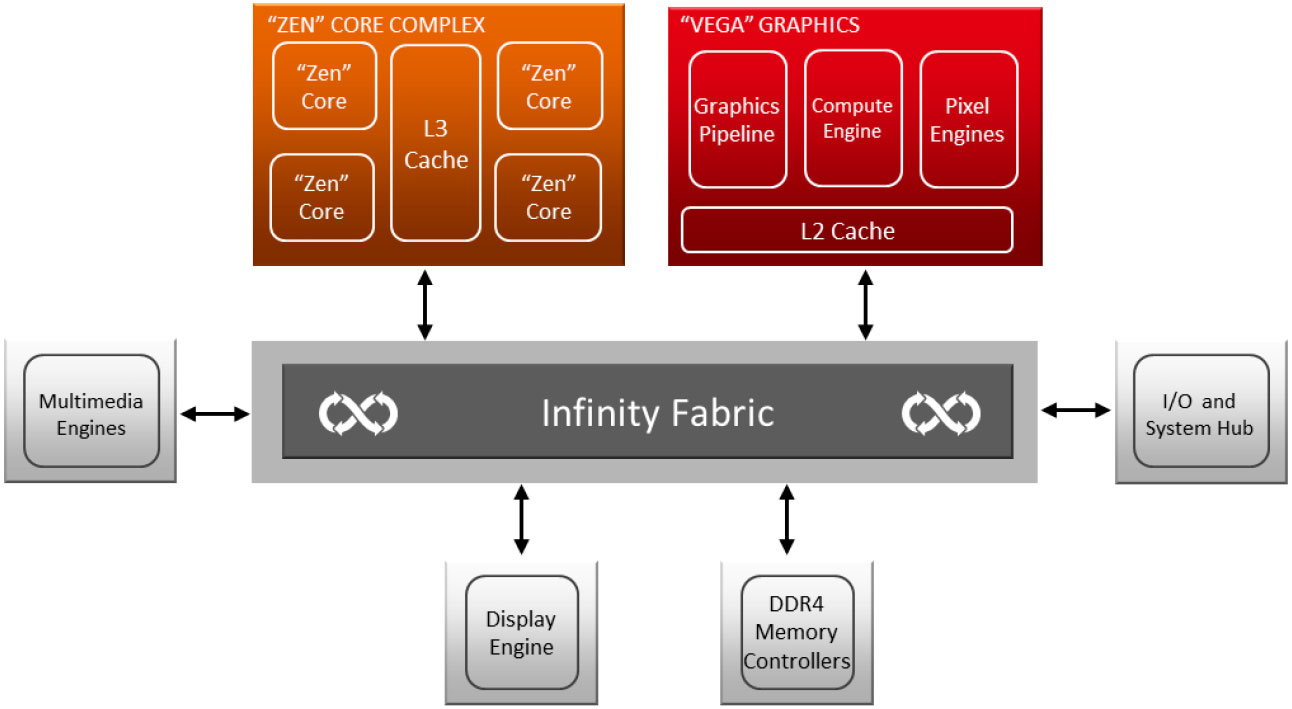
Comme nous l'indiquions en débutant ce dossier, les nouveaux APU d'AMD sont issus de la fusion de Zen et Vega. Pour ceux qui ne seraient pas familiers avec ces architectures, nous vous invitons à consulter les dossiers que nous leur avons consacrés ici et là. Voici représenté schématiquement par AMD, ces nouveaux APU. On trouve donc les parties CPU et GPU, mais également les contrôleurs mémoire et la partie SoC du processeur. Tout ce petit monde est interconnecté sans surprise à l'aide de l'Infinity Fabric, l'interface "à tout faire" d'AMD :
![Schéma de principe Raven Ridge [cliquer pour agrandir]](/images/stories/articles/cpu/raven_ridge/raven_ridge_diagram_t.jpg "Cliquédélique !")
Schéma de principe Raven Ridge
Alors que tous les Ryzen Summit Ridge commercialisés jusqu'à présent s'appuyaient sur un seul et unique die Zeppelin comprenant 2 CCX (4 coeurs + 8 Mo L3), les nouveaux venus utilisent cette fois un tout nouveau die, incluant le GPU ainsi qu'un seul et unique CCX. Ce dernier contient toujours 4 coeurs Zen, par contre le cache L3 passe de 8 Mo à 4 Mo. A priori une mauvaise nouvelle, mais peut-être pas tant que cela en fait, puisque la quantité c'est bien, mais la vitesse c'est encore mieux et d'après AMD, la situation changerait en mieux à ce niveau.
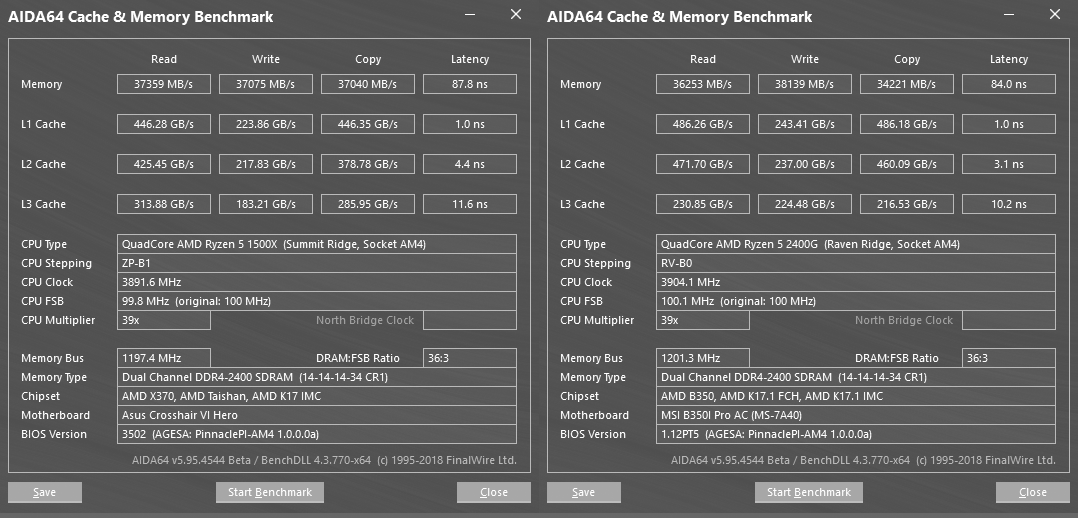
Une des faiblesses identifiées des Summit Ridge, provient de la latence des caches et mémoire, du fait de l'interfaçage via Data Fabric (commutateurs entre "modules" du CPU). AMD indique que ce point est en progrès (sans expliciter pourquoi), ce qu'AIDA64 semble confirmer tout en indiquant également une baisse de certains débits. Tout ceci nécessite donc d'être approfondi, principalement du fait de la non adaptation du logiciel dans sa version actuelle, telle qu'indiquée en fin de test par un message d'avertissement. Enfin, AMD précise également, que la rédution du cache permet d'atteindre plus facilement des fréquences élevées.
![Latences et débits des caches et mémoires selon AIDA64 [cliquer pour agrandir]](/images/stories/articles/cpu/raven_ridge/cache_t.png "Cliquédélique !")
Latences et débits des caches et mémoire Summit Ridge vs Raven Ridge
A ce sujet, Precision Boost, le Turbo inauguré par Ryzen, passe ici en version 2. Alors que le nombre de coeurs sollicités était le levier principal de la version d'origine (si 2 coeurs ou moins sont actifs, alors le CPU utilise sa fréquence maxi sous couvert de respecter le TDP, puis bascule sur une fréquence moindre au-delà), la charge réelle des coeurs est à présent prise en compte pour autoriser des fréquences intermédiaires, et ce (toujours) avec une granularité de 25 MHz.
Ainsi, si par exemple 3 coeurs sont sollicités mais faiblement, Precision Boost 2 autorisera une fréquence supérieure à celle permise par la première itération de ce Turbo. C'est donc un fonctionnement partiellement opportuniste qui est adopté à présent, AMD fournit ci-dessous une vue conceptuelle qui ne traduit pas le fonctionnement réel de Precision Boost 2, mais symbolise la plage de gains escomptables avec cette nouvelle version du Boost.
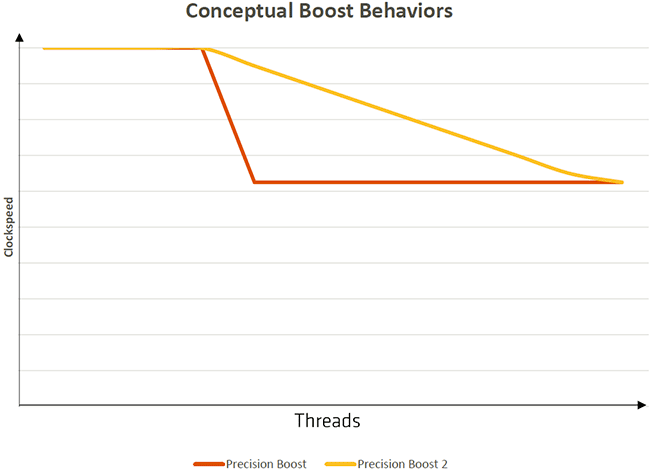
Un Turbo plus évolué
Un mot rapide sur la partie SoC qui évolue elle aussi avec la prise en charge native de 4 ports USB 3.1 Gen 2 (ainsi qu'un USB 2.0 et un 3.0), alors que Summit Ridge se contentait de 4 USB 3.0 max. (ou USB 3.1 Gen 1 pour le marketing). Point remarquable, deux d'entre-eux supportent l'Alternate Mode for Display Connectivity au travers de l'USB Type-C, de quoi gérer la vidéo via cette interface pour peu que les cartes mères soient prévues pour..... ce qui n'est malheureusement pas encore le cas.
A cela, s'ajoute 2 ports SATA, mais on notera surtout la réduction du nombre de lignes PCIe 3.0, qui passent de 24 à 16. Il n'en restera donc que 8 utilisables pour une carte graphique externe (ce qui ne devrait pas la brider pour autant), toutefois, on choisit un APU généralement pour s'en passer. Les 8 autres se partagent entre les ports PCIe, NVMe, SATA Express facultatifs et le chipset (4X), sauf pour les X300/A300 (qui utilisent un lien SPI dédié mais sans fonctionnalités supplémentaires à celles du SoC).

Passons à présent à la partie GPU : c'est l'architecture Vega qui est à la manoeuvre avec 2 versions différentes selon l'APU : Vega 11 pour le R5 2400G et Vega 8 pour le R3 2200G, suivant le nombre de CU (Compute Unit) activés au sein du die et la fréquence de fonctionnement. De quoi atteindre une puissance de calcul de 3,5 TFlops en pic pour le plus rapide, un résultat impressionnant pour un APU, même si comme toujours, cette caractéristique ne "fait pas tout" dans les performances d'un GPU.
Pour le reste, les caractéristiques sont identiques, avec un seul pipeline graphique qu'AMD nommait précédemment Shader Engine, conduisant à une géométrie limitée (un seul triangle par cycle mais avec des optimisations introduites par Vega via les Primitives Shaders). Le DSBR (Draw Stream Bining Rasterizer) est également de la partie : il s'agit de gains opportunistes via Tile Rendering, permettant d'éviter la rastérisation (découpe des triangles en pixels) sur certaines portions (Tile) d'un scène.
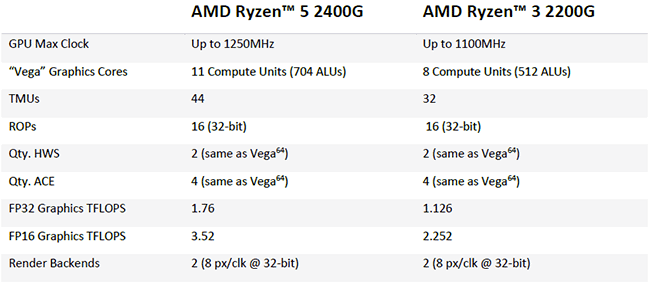
Chaque CU est identique à ceux que l'on trouve sur les RX Vega, c'est à dire composés de 4 TMU pour le texturing et 64 unités de calcul (ALU). Ces dernières prennent en charge la demi-précision (16-bit) à double vitesse (Rapid Packed Math). AMD a également choisi de conserver l'intégralité des ACE présents sur Vega 10, malgré la réduction drastique du nombre d'unités de calcul pour Vega 11 (704), probablement dans une optique d'utilisation Compute de ces dernières. En sortie, on retrouve sur les 2 versions, 16 ROP chargés d'écrire en mémoire.
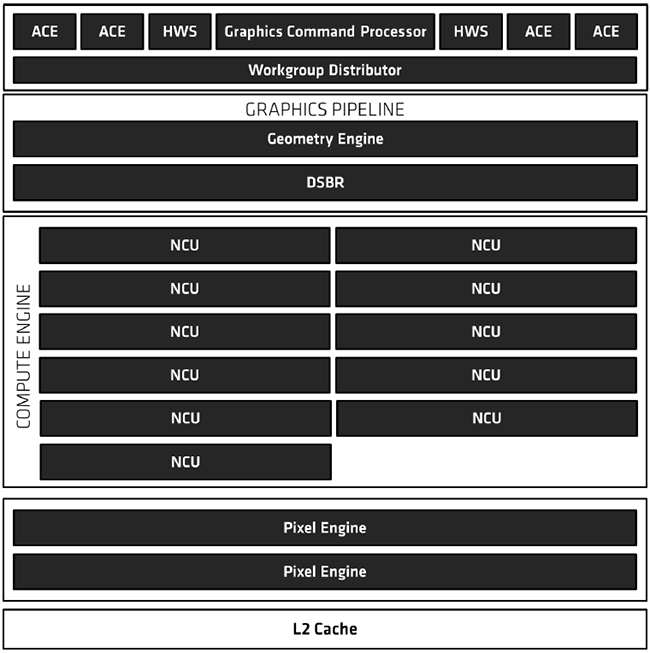
Diagramme de Vega 11
Pour conclure cette rapide description de la partie graphique intégrée au die des Raven Ridge, on notera que les fonctionnalités d'encodage/décodage sont strictement les mêmes que celles assurées par les RX Vega, une bonne chose.
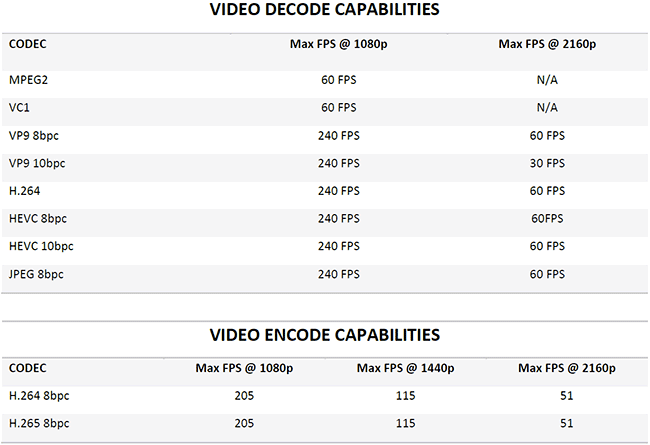
Et ça encode, et ça décode, et bim !
Tout ce petit monde (4,94 Milliards de transistors) tient sur un die toujours gravé en 14 nm par Global Foundries, sur un peu moins de 210 mm². Il est donc plus ou moins équivalent à Zeppelin (~213 mm² pour 4,8 Milliards de transistors), alors qu'il n'embarque qu'un seul CCX (qui plus est avec un cache L3 deux fois plus petit), le GPU Vega est toutefois passé par là !
![le die raven ridge [cliquer pour agrandir]](/images/stories/articles/cpu/raven_ridge/die_t.jpg "Enlarge your pe...icture") Le die des Raven Ridge
Le die des Raven Ridge
Maintenant que nous avons rapidement décrit Raven Ridge, passons page suivante aux processeurs reçus.
|
|
| Un poil avant ?Un SMIC chinois pour graver en 28 nm ! | Un peu plus tard ...Zelda avec l'Unreal Engine 4, et non ce n'est pas CryZENx ! | |