Hard du hard • Ça fonctionne comment, un processeur ? (Partie 1) |
• 12 Mars 2018



Revenons aux bases : un processeur est fait de transistors. Sans rentrer dans les détails de la physique des tripôles, un transistor permet de créer un "interrupteur" : le courant passe (ou non) suivant la valeur logique d'un troisième fil. A partir de cette brique de base sont fabriquées des bascules, un assemblage de transistors pouvant retenir une valeur (on a alors un registre à 1 bit !) ainsi que des portes logiques, c'est à dire des unités permettant la résolution matérielle de problèmes d'algèbre booléenes. Si le mot algèbre vous a déclenché des remontées acides, pas de problèmes : il s'agit simplement de calculs ou d'opérations logiques ("ou", "et", ...) apliqués à des nombres binaires.
Petite parenthèse : ce mode de codage n'autorise que les entiers à être représentés. Pour des nombres à virgule (ou des nombres très grands), il faut trouver une autre solution : c'est la représentation à virgule flottante, qui se base sur la multiplication ou la division d'un entier relatif par une puissance de 2. Nous ne couvrirons pas les détails ici, il faut simplement retenir que les unités du calcul nécessaires aux opérations flottantes sont bien distinctes de celles opérant sur les entiers (et plus lentes, en particulier pour la division). Notamment, on parle d'ALU (Unité Arithmétique et Logique) pour les calcul sur des entiers, et FPU (Unité à Virgule Flottante) pour les décimaux.
![L'Intel 486 DX [cliquer pour agrandir]](/images/stories/articles/cpu/archi-cpu/intel486-dx_t.jpg "Si vous cliquez, vous cliquez.")
L'i486-DX : autant au niveau du dessus que du dessous, cela a bien changé !
Autrefois, les processeurs étaient constitués d'un assemblage de transistors qui se contentait de lire une à une les instructions assembleur et de les exécuter les unes à la suite des autres (parle d'exécution séquentielle). La fréquence était alors le facteur déterminant la performance du CPU. Exprimée en Hertz (Hz), elle donne le nombre d'instructions effectuées par seconde. Ainsi, qu'un CPU soit Intel ou AMD, un processeur cadencé à 200 MHz était deux fois plus rapide qu'un autre cadencé à 100Mhz. Pour fournir des processeurs de plus en plus véloces, la fréquence a dûe être augmentée, atteingnant des sommets avec le Pentium 4 chez Intel, où un problème de taille s'est révélé : le dégagement thermique.
Alors que les bleus annonçait des processeurs à 10 GHz comme limite, l'architecture du Pentium 4 s'est arrété un peu de dessous des 4 GHz, car il devenait impossible de dissiper l'énergie nécessaire à l'alimentation des machines. Ce phénomène provient d'une loi physique stipulant que le dégagement thermique suit la tension de manière quadratique et la fréquence linéairement : si vous doublez la fréquence, et vous doublez la chaleur, sans compter l'augmentation de tension nécessaire à stabiliser cette cadence plus élevée... Depuis, de nouveaux mécanismes ont été développés pour augmenter l'IPC (nombre d'Instruction Par Cycle). C'est pourquoi il est aujourd'hui difficile de comparer les performances relatives des processeurs entre eux, car certains mécanismes sont présents et d'autres non, et leur impact peut être très prononcé selon l'utilisation.
On ne va pas s'appesantir là-dessus : le principe est juste d'augmenter la fréquence en fonction de la charge de travail demandée et du nombre de cœurs solicités (pour la description complète d'un cœur, attendez la seconde partie !). Plus le programme nécessite de cœurs et moins la fréquence sera augmentée. Sous boost, le CPU fait donc plus d'opérations par seconde, accélérant ainsi l'exécution au prix d'une consommation supérieure. De nos jours, le phénomène inverse existe également : réduire la fréquence au repos pour diminuer la chauffe : par exemple un i5-6600k mouline à 3,5 GHz de base (lors d'un encodage vidéo très lourd utilisant les 4 cœurs par exemple), mais il grimpe à 3,9 GHz si un seul coeur est utilisé ; par contre - hors charge - sa fréquence dégringole à 800 MHz, pas de panique donc si cela vous arrive !
Une amélioration apparue chronologiquement très tôt est le pipeline. Il permet à plusieurs instructions de s'exécuter en même temps, sans pour autant changer la manière de programmer. Le principe consiste à découper l'exécution d'une instruction en plusieurs étapes, de manière à pouvoir exécuter le début de l'instruction suivante alors que l'instruction courante n'est pas encore terminée. Exemple classique : dans un restaurant self-service, vous n'attendez pas que la personne devant vous ait fini de payer pour prendre votre plateau, mais au contraire vous avez juste une étape de retard par rapport à elle.
Une des raisons de l'échec du Pentium 4 fut l'utilisation d'un pipeline bien trop long, entre 20 et 31 étapes (on parle aussi de stages). Bien que cela ait permis une montée en fréquence plus aisée (plus il y a d'étapes, moins il y a de choses à faire en une étape, et plus la fréquence peut augmenter), cela entraîne des surcoûts important lors des instructions de branchment, car il faut alors vider le pipeline le temps que le compteur ordinal soit mis à jour vers la nouvelle adresse.
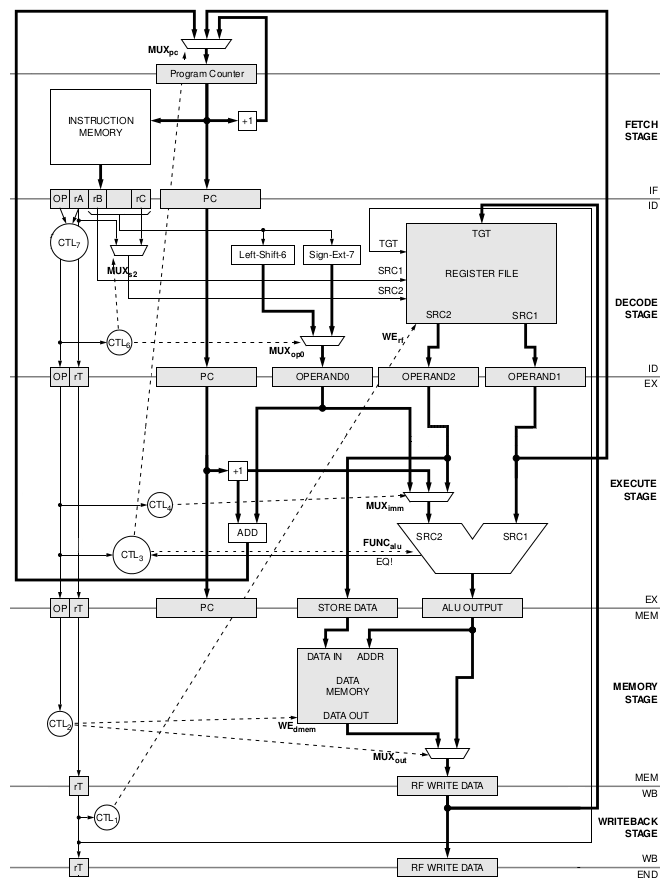
![Le pipeline d'un CPU RiSC-16 [cliquer pour agrandir]](/images/stories/articles/cpu/archi-cpu/cpu-pipeline-risc16_t.png "Même pas cap' de cliquer")
Un RiSC 16 bits et son merveilleux pipeline (Crédit : Université de Maryland)
| Identifieur | Nom complet | Fonction |
|---|---|---|
| IF | Instruction Fetch | Chercher la prochaine instruction |
| ID | Instruction Decode | Séparer les différentes opérandes en fonction de l'opcode, aller chercher les valeurs conenues dans les registres |
| EX | Execute Stage | Effectuer les calculs |
| MEM | Memory | Lire/Ecrire en RAM |
| WB | Writeback | Ecrire - si besoin - dans le registre cible |
On notera qu'à chaque cycle, les valeurs de l'opcode et du registre de destination sont transmises à l'étage suivant (carrés "OP" et "rT", à droite). Le Register File contient les valeurs stockées dans les registres, alors que l'Instruction Memory contient le programme exécuté (sur les systèmes actuels, il est fusionné avec la RAM), et Data Memory n'est autre que cette RAM.
Le principe est relativement simple : pour éviter d'attendre lors d'un branchement conditionnel (va ici, sinon continue), le processeur va faire des suppositions sur les instructions à charger. Dans le cas ou l'addresse est correctement prédite, l'exécution continue ; mais le pipeline doit être vidé dans le cas contraire, entraînant un temps suplémentaire. Ce mécanisme est néanmoins particulièrement efficace dans le cas de boucles, ou les branchements sont très prévisibles et très impactants sur les performances.
Les premiers prédicteurs de branchement étaient assez sommaires, en se contentant de charger à la dernière adresse utilisée lors de la dernière exécution du branchement ; la plupart de ceux utilisés de nos jours sont implémentés avec un compteur à 4 états (oui sûr/oui/non/non sûr), que l'on modifie en fonction du branchement réellement pris. Cela permet, dans le cas des boucles, de ne se tromper qu'une à deux fois (à la sortie de la boucle et éventuellement à la première itération). En effet, la condition de sortie n'étant vraie qu'une seule fois, ce n'est pas suffisant pour faire changer la prédiction d'un système à 4 états (on passe d'un état "oui sûr" à "oui" en se trompant à la sortie de la boucle) : le prédicteur de branchement peut ainsi se révéler particulièrement efficace.
Il existe d'autres techniques tels l'Eager Execution consistant à évaluer les deux chemins d'exécutions possibles et ne garder par la suite que le bon. De plus, les Chargement Spéculatifs (Speculative Loads) permettent de charger en avance une variable avant de connaître son adresse exacte. Par exemple, lorsque l'on souhaite accéder à des pointeurs de pointeurs, du type :
maClasse->suivante->suivante->monAttribut
Le processeur est théoriquement obligé d'attendre la valeur de :
maClasse->suivante
Avant d'accéder encore au second champ :
suivante
Et enfin à la valeur :
monAttribut
...souhaitée. Avec des chargements spéculatifs (qui se révèlent efficaces surtout lors d'opérations sur des tableaux), le processeur peut "deviner" à l'avance la valeur contenue dans maClasse->suivante et ainsi accélérer l'exécution.
Out-of-Order et les micro-opérations : décomposer pour mieux régner
Une évolution notable a été le passage à un fonctionnement de type OoO : Out-of-Order. Pour comprendre ce que cela signifie, il est nécessaire de garder en tête que toutes les instructions ne prennent pas le même temps à s'exécuter. Par exemple, la chargement d'une variable depuis la RAM peut prendre jusqu'à 200 cycles d'horloge, là ou une addition de deux registre ne prends que quelques cycle ! Pour éviter de bloquer le CPU en attendant un chargement mémoire, les autres instructions indépendantes peuvent être exécutées. Il en résulte que l'ordre d'exécution des instructions n'est pas le même que leur ordre de soumission. De manière plus large encore, les instructions présentent dans une certaine fenêtre (224 instructions sur l'architecture Skylake) autour de l'instruction courante peuvent être totalement réordonnées en fonction de ce que le CPU juge optimal. Pas de panique, ce fonctionnement est totalement transparent du point de vu de programmateur, si bien que - hors failles de sécurité - aucun changement dans le code n'est nécessaire pour tirer parti de cette amélioration.
Pour ce qui est du vocabulaire, un CPU qui n'est pas Out-of-Order est dit In Order. C'était le cas des premiers Atom, d'où leur performances ; et de nombreux processeurs ARM (citons par exemple le Cortex-A53 présent dans le Snapdragon 435). Pour les Out-of-Order, ce sont tous les autres : la gamme d'AMD, la gamme desktop et serveur d'Intel, ainsi que les plus gros cœurs ARM (par exemple les cœurs Kryo des Snapdragons 825).
Nous avions vu auparavant que les processeurs pouvaient être RISC (peu d'instructions disponibles, mais assez rapides) ou CISC (instructions plus puissantes et plus lentes). L'x86 était à la base du CISC, mais a dû évoluer pour apporter toujours plus de performances. Les instructions complexes sont désormais découpées en micro-ops ou micro-instructions, plus facile à réordonner et exécuter. Une fois l'instruction coupée en morceaux, les micro-ops sont redirigées vers des ports reliés aux unités de traitement correspondantes.
Une manière simple et relativement efficace de gagner en performance est de rajouter des nouvelles instructions, appelées aussi extentions, car elle étendent celles de l'ISA de base, par exemple en permettant d'additionner deux tableaux via des unitées de calcul dédiées. Depuis le premiers CPU x86, de nombreuses intructions ont été ajoutées, en commençant par le MMX (MultiMedia eXtention, utilisées pour le décodage vidéo) introduit en 1995, jusqu'au SSE puis SSE2/SSE3, et enfin l'AVX / AVX-2 / AVX-512 intégré dans Skylake-X. Si ces dernières sont dites vectorielles, c'est parce qu'elles permettent de traiter directement des vecteurs, c'est à dire des tableaux, des zones contigues en mémoire, sur lesquelles une même opération est itérée. On parle alors de SIMD, pour Single Instruction Multiple Data : une seule instruction mais plusieurs opérations.
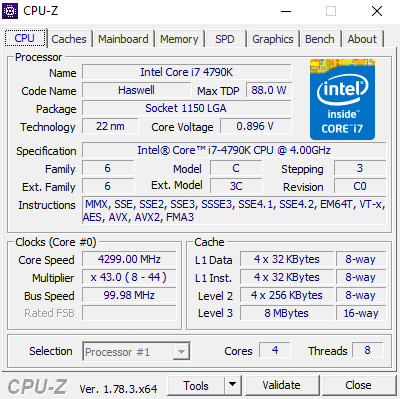
On peut voir les extentions supportées avec CPU-Z, case "Instructions" (MMX, SSE, AVX, DTC, ...). Toutes ne sont par contre pas vectorielles !
Cependant, les programmes doivent être recompilés et les compilateurs réécrits pour tirer parti de ces nouvelles instructions ; de plus, le gain n'est pas toujours en rendez-vous dans des cas pratiques. Il suffit en effet que l'instruction vectorielle adaptée à votre programme vous permette d'additionner deux tableaux de taille 200 et que vous n'avez que 100 valeurs : on se doute bien que le CPU sera sous-utilisé.
Pour comprendre un peu plus en détails la vectorisation, penchons-nous sur les instructions SSE et leurs améliorations, l'AVX. A la base, les extentions Streaming SIMD Extentions (SSE !) proposaient 8 registres 128 bits nommés xmm0 jusqu'à xmm7, ainsi que les opérations de base sur ces registres : chargement, rangement, conversion (chargement depuis un registre général), et les classiques opérations arithmétiques telles que l'addition/soustraction/multiplication/division/inverse/racine/inverse de la racine/MAX/MIN, toutes pouvant opérer soit sur une seule valeur (Scalar) stockée dans un registre xmm, soit sur 4 flottants 32 bits contenus toujours dans une registre xmm (Packed). Le SSE2 vient élargir ces fonctionnalité en ajoutant des calculs sur les entiers et la double précision : on peut alors faire tenir (et effectuer les opérations sur) 2 entiers/flottants 64 bits, ou bien 4 en 32 bit, ou encore 8 entiers 16 bits, et même 16 valeurs 8-bits. Le SSE3 ajoute par la suite des instructions permettant la prise en charge d'une même opération sur deux couples de quatre registres.
D'autres instructions tels que les permutations des valeurs au sein d'un registre xmm et le produit scalaire sont rajoutées par la suite dans les extensions SSSE3 et SSE4. Pour replacer dans la chronologie Intel, le SSE apparait avec les Pentium III en 1999 ; et s'améliorera jusqu'à l'AVX (Advance Video eXtensions), introduit sur Sandy Bridge en 2013. Ces nouvelles instructions étendent simplement les opérations flottantes du SSE en rajoutant 8 autres registres et en doublant leur taille pour atteindre 256 bits. Les registres sont alors renommés en ymm, mais pour des questions de compatibilités, les xmm restent toujours utilisables.
L'AVX2 comble assez logiquement les trous de l'AVX en supportant les opérations entières sur les ymm. Enfin, l'AVX-512, uniquement présent sur les Xéon Phis KNL et les Skylake-X, doublent encore une fois la taille et le nombre de registres pour passer à 32 registres 512 bits nommés zmm.
|
|
| Un poil avant ?Adoption de FreeSync : enfin sur XBox One (MAJ) | Un peu plus tard ...Enfin un test pour le Quadstellar | |
| 1 • Préambule |
| 2 • Registres, assembleur et instructions |
| 3 • |
| 4 • Conclusion (avant la suite) |