Preview • Le point sur le GT300 "Fermi" de Nvidia |
• 01 Octobre 2009



Preview • Le point sur le GT300 "Fermi" de Nvidia |
• 01 Octobre 2009

Voilà donc ce fameux die de Fermi vu de près. L'impressionnant total de 3 milliards de transistors est atteint grâce à la gravure en 40nm, un total qui donne presque le vertige, comparé aux 1.4 milliards de transistors du GT200, ou même aux 2.15 milliards du Cypress d'AMD, lui aussi en 40nm.
Les unités de calcul sont également en forte hausse, ainsi si la GTX 285 par exemple en possédait 240, le Fermi lui disposera de 512SP, soit plus du double ! Nvidia annonce par ailleurs des performances en calcul "double précision" qui pourront être jusqu'à multipliées par 8.
Enfin grandes nouveautés mises en avant par la marque : la correction d'erreurs ECC sera de la partie pour une meilleure fiabilité, et il sera également possible de compiler en C++ pour le Fermi (langage qui vient donc s'ajouter à ceux déjà supportés : C, Java, Python, OpenCL, DirectCompute...), qui serait une pionnière dans le domaine de la programmation à ce niveau. Vous noterez le titre de la diapositive : "l'âme d'un supercalculateur dans le corps d'un GPU", voila qui confirme l'orientation prise : le Fermi a été conçu en pensant aux applications professionnelles et logicielles, pas que pour le jeu. Un couteau suisse de la 3D en quelque sorte...
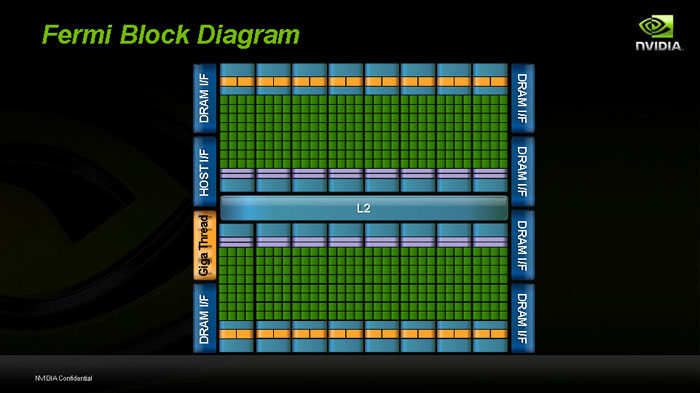
Voici le diagramme du GT300 par "blocs". Première information très intéressante montrée par ce diagramme : la présence de 6 "DRAM I/F", qui sont chacun de 64bits. Le calcul est simple : 6*64 = 384bits, le Fermi disposera donc d'un bus mémoire 384bits, associé à de la GDDR5. Une combinaison qui était très espérée sur les HD5800 mais qui ne s'est pas révélée exacte. Le GT300 en sera lui bel et bien doté, et l'on peut s'attendre à une bande passante phénoménale donc. Il est également annoncé que le Fermi pourra disposer de 1.5, 3 ou même 6Go de GDDR5 !
Pour faire simple ensuite, le diagramme nous montre également que le Fermi se compose de 16 SM (Streaming Multiprocessors), placés de chaque côté d'une mémoire cache L2 centrale.
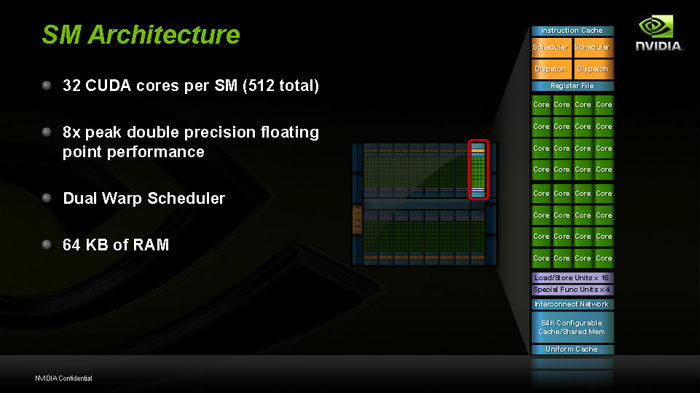
Voici le gros plan d'un de ces SM. Ils contiennent chacun de la mémoire cache L1, et bien sûr des unités d'exécution représentées par les petits carrés verts. On en compte 32 par SM d'où les 512SP au total du die.
Au total, chaque SM disposera de 64Ko de mémoire, dispatchés entre la mémoire partagée et le cache L1. Viendra donc s'ajouter encore à cela la mémoire cache L2, 768Ko par SM, une première pour un GPU.

Nvidia ne se contente pas d'annoncer qu'il y aura bien plus de cores à son GT300 comparé au GT200 (512 contre 240), il indique également que l'efficacité des coeurs du Fermi sera décuplée grâce à l'adoption d'un nouveau standard de calcul en virgule flottante : le IEE 754-2008, qui serait selon eux ce qui se fait de plus performant à l'heure actuelle. Tout serait de plus optimal pour un usage 64bits, qui va tendre à se démocratiser dans un avenir proche y compris sur les PC grand public (depuis le temps qu'on l'attend...).

Comme nous l'avons déjà dit, le Fermi sera la première puce graphique à voir apparaître une véritable hiérarchie dans la présence de la mémoire cache de son GPU, à la manière finalement des CPUs. Chaque coeur aura ainsi à sa disposition tout d'abord la mémoire partagée et le cache L1 pour un total de 64Ko disponibles. Le cache L1 pourra ensuite faire appel au cache de second niveau, disposant lui de 768Ko supplémentaires par SM (32 coeurs), plus lent que le L1 mais presque le décuple en taille. Enfin seulement se trouvera l'accès à la mémoire GDDR5 de la carte. Un choix qui pourrait s'avérer très payant !

Autre information quant à cette mémoire : toutes les mémoires internes que nous avons citées seront ECC, c'est-à-dire qu'elles disposeront d'une protection contre les "erreurs". La GDDR5 supportera également l'ECC.
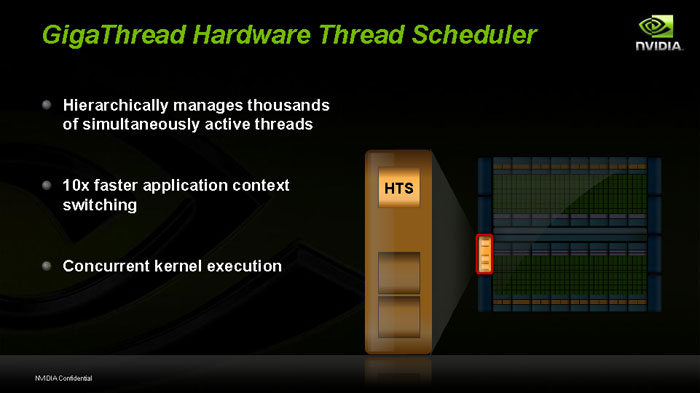
On le sait, l'avenir est au parallélisme pour améliorer le temps d'exécution des tâches. La solution adoptée par Nvidia avec le GT300 porte le nom de "GigaThread", capable selon la firme de gérer des milliers de threads simultanément, et de passer de l'un à l'autre 10 fois plus rapidement qu'auparavant.

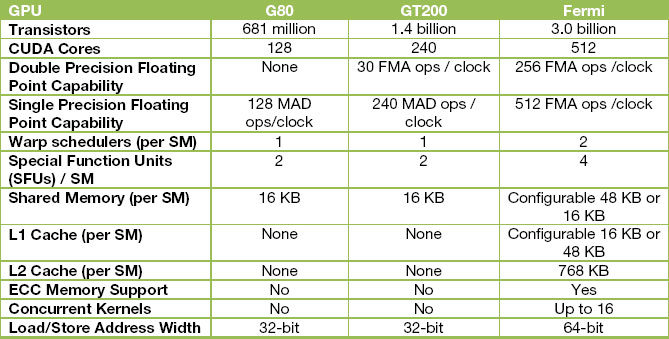
Un beau tableau valant souvent mieux qu'un long discours, voici pour résumer donc les principales caractéristiques du Fermi, comparé aux deux architectures précédentes majeures du caméléon, les G80 et GT200.
|
|
| Un poil avant ?Une nouvelle révision pour le Megahalems | Un peu plus tard ...La GTX260 plus courte et mieux refroidie chez Zotac | |
| 1 • Préambule |
| 2 • Présentation |
| 3 • Les objectifs du caméléon |
| 4 • |
| 5 • La première carte Fermi en photo |





















