Test • Nvidia GeForce RTX 4090 |
• 11 Octobre 2022



Test • Nvidia GeForce RTX 4090 |
• 11 Octobre 2022
Après avoir décrit la partie "traditionnelle" de l'architecture du GPU page précédente, jetons à présent un coup d'œil aux différentes unités spécialisées incluses, qui elles, ont évolué significativement avec cette nouvelle génération Ada.
Turing avait marqué une rupture en étant la première architecture à inclure des unités dédiées à l'accélération matérielle du Ray Tracing. Plus précisément de l’algorithme BVH (Bounding Volume Hierachy), vous retrouverez tous les détails le concernant au sein de cette page. Ampère utilise de son côté des RT cores de seconde génération, disposant d'un débit doublé pour le calcul des intersections des rayons avec les triangles, ainsi qu'une unité accélérant l'application du flou cinétique lors des rendus. Avec ADA Lovelace, Nvidia double à nouveau le débit pour le calcul des intersections rayons/triangles, portant à fois 4, le gain par rapport à la première itération des RT Core (Turing) dans ce domaine.
Ensuite, les verts ont inclus au RT Core d'Ada, une unité capable d'effectuer les opérations Alpha (transparence) 2 fois plus rapidement. En effet, les développeurs utilisent fréquemment le canal alpha d'une texture pour découper sans consommer trop de ressources, des formes complexes, ou plus généralement pour représenter la translucidité. Une feuille peut ainsi être décrite à l'aide de quelques triangles, en utilisant le canal alpha d'une texture pour "détourer économiquement" la forme complexe. Il est également possible de faire une approximation satisfaisante d'une flamme complexe, par le biais de cette technique.

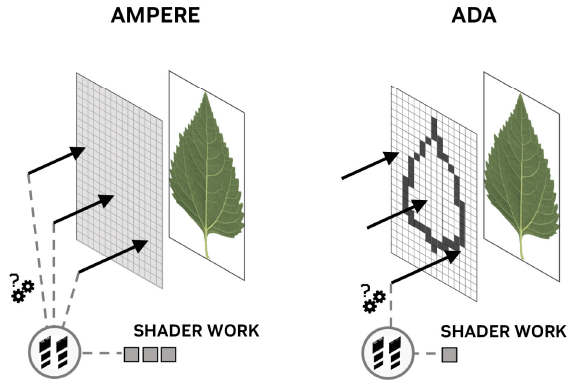
Jusqu'à présent, un développeur désireux d'incorporer ces types de contenu dans une scène utilisant le RT, devait les marquer comme non opaques. Lorsqu'une feuille est par exemple susceptible d'être touchée ou non par un rayon, un shader est invoqué pour déterminer comment traiter l'intersection, et ce même si cette dernière se produit ou non, ce qui entraîne un coût non négligeable. Plus précisément, lorsqu'un groupe de rayons est projetée vers des objets non opaques, les requêtes de rayons individuels peuvent nécessiter plusieurs invocations de shader pour être résolues, alors que certains rayons se terminent immédiatement. Il en résulte de nombreux threads actifs persistants, et une inefficacité proportionnelle.
Pour améliorer cela, les ingénieurs de NVIDIA ont donc ajouté un moteur dénommé Opacity Micromap au RT Core d'Ada. Ce dernier, que l'on pourrait traduire par microcarte d'opacité, est un maillage virtuel de micro-triangles, chacun avec un état d'opacité que le RT Core utilise pour résoudre directement les intersections de rayons avec des triangles non opaques. Plus précisément, les coordonnées d'une intersection sont utilisées pour adresser l'état d'opacité du micro-triangle correspondant. 3 états sont possibles au sein de cette carte : opaque, transparent ou inconnu. S'il est opaque, un impact est enregistré et renvoyé. S'il est transparent, l'intersection est ignorée et la recherche d'une intersection se poursuit. S'il est inconnu, le contrôle est renvoyé au SM, qui va faire appel à un shader ("anyhit") pour résoudre l'intersection.
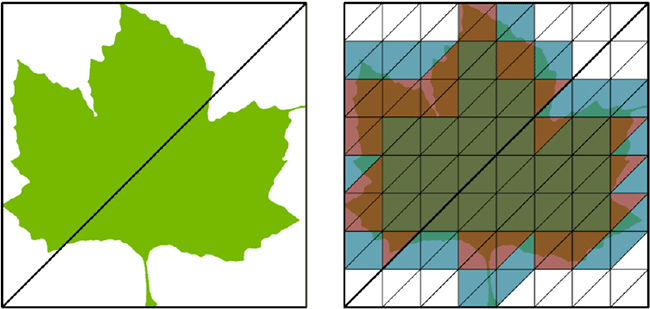
Ces mailles peuvent être dimensionnées de un à seize millions de micro-triangles, avec un ou deux bits associés à chacun d'entre eux. À titre d'exemple, la figure ci-dessus montre une feuille d'érable décrite à l'aide de deux triangles et d'une texture alpha. Sur le schéma, les zones transparentes sont blanches, la feuille n'est pas présente sur ces dernières. Celles vert foncé correspondent à des zones opaques de la feuille, enfin les rouges et bleus correspondent à des zones d'opacité mixte (inconnue). Le moteur Opacity Micromap marque ainsi 30 des micro triangles comme transparents, 41 comme opaques et 57 comme inconnus.
Cela signifie que plus de la moitié de la feuille est entièrement caractérisée et que plus de la moitié des rayons coupant ces triangles, soit manquent la feuille, soit la touchent sans ambiguïté. Le RT Core d'Ada peut donc entièrement caractériser ces rayons sans avoir à invoquer le moindre shader pour cela, tout en préservant la pleine résolution et la fidélité de la texture alpha d'origine. Bien sûr, lorsque l'état est inconnu, il faut toujours faire appel à un shader pour sa résolution, mais leur nombre est largement réduit du fait de l'action préalable de l'Opacity Micromap Engine.
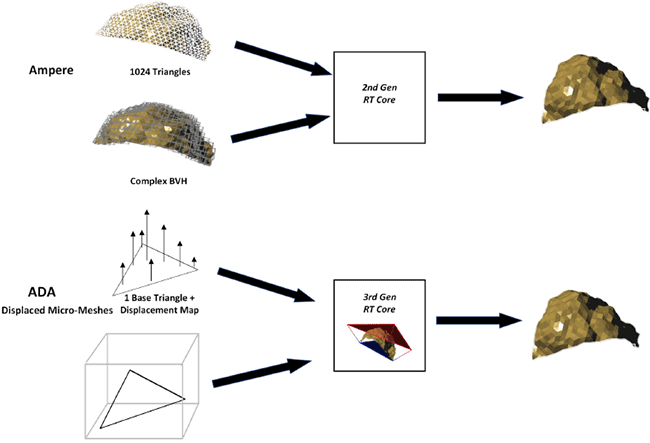
Dernier point d'amélioration des RT Core d'ADA, le Displaced Micro-Meshes ou DMM. La complexité géométrique continue d'augmenter à chaque nouvelle génération, toutefois, les performances lors du traçage des rayons, sont faiblement impactées par cette dernière. Ainsi, dans une scène en Ray Tracing, une multiplication par cent de la complexité géométrique, ne conduira qu'à doubler le temps de traçage des rayons. Cependant, la création de la structure de données (BVH) qui rend possible cette "petite" augmentation de temps lors du traçage, nécessite elle un temps et une mémoire à peu près linéaires à l'augmentation de la complexité géométrique. Ainsi, 100 fois plus de géométrie pourra nécessiter jusqu'à 100 fois plus de temps pour créer le BVH et 100 fois plus de mémoire pour le stocker.
Les RT Cores de troisième génération intègrent donc le Displaced Micro-Meshes, afin d'aider à relever les deux défis consécutifs d'une complexité géométrique élevée : les performances lors de la construction du BVH et l'empreinte mémoire/stockage. Le stockage des Assets et les coûts de transmission de ces derniers sont également réduits. Voilà comment les verts définissent DMM :
Nvidia a développé le DMM comme une représentation structurée de la géométrie qui exploite la cohérence spatiale pour être compacte (compression) et exploite cette structure pour un rendu efficient avec un niveau de détail intrinsèque (LOD) et une animation/déformation légère.
Coté clarté on a déjà fait mieux. Il s'agit en fait de micro-géométrie, Lors des opérations faisant appel au Ray Tracing, la structure du DMM est utilisée pour éviter une forte augmentation des coûts de construction BVH (temps et espace), tout en préservant une traversée BVH efficace. Ainsi, lors des phases de rastérisation, le niveau de détails (LOD) intrinsèque au DMM, permet de rastériser les primitives de tailles adéquates via des Mesh Shaders ou Compute Shaders.
 Ce crabe est composé de triangles de base représentés en rouge (à gauche), avec des détails géométriques supérieurs représentés par les micro-meshes (rouge également) à droite
Ce crabe est composé de triangles de base représentés en rouge (à gauche), avec des détails géométriques supérieurs représentés par les micro-meshes (rouge également) à droite
Le DMM est donc en fait une nouvelle primitive géométrique, qui a été co-conçue par le moteur de micro-géométrie inclus dans le RT Core (troisième génération). Chaque Micro-Mesh est définie par un triangle de base et une carte de "déplacement", contenant la valeur de ce dernier pour chaque micro-triangle. Le moteur peut ainsi générer à la demande des micro-triangles à partir de cette dernière, afin de résoudre les intersections entre les rayons et les Micro-Meshes, et ce jusqu'à atteindre le micro-triangle touché par le rayon. La carte est façonnée de la sorte : les sommets des micro-triangles constituent une grille barycentrique de puissance deux, et leurs coordonnées sont utilisées pour traiter directement les déplacements des micro-vertex.
A l'instar de l'architecture classique, Nvidia ne dévoile finalement que bien peu de choses concernant les Tensor Cores d'Ada. Pour rappel, ces derniers sont des cœurs de calculs spécialisés à hautes performances, qui sont adaptés aux opérations mathématiques de multiplication et d'accumulation matricielles, particulièrement utiles dans les applications IA et HPC. Ils peuvent donc à la fois servir pour l'apprentissage en profondeur des réseaux de neurones (Deep Learning), mais aussi pour les fonctions d'inférence, dont le DLSS est une des mises en œuvre les plus célèbres. Par rapport à Ampere, Ada fournit plus du double des TFLOPS FP16, BF16, TF32, INT8 et INT4 et inclut également le moteur Hopper FP8, offrant plus de 1,3 PetaFLOPS de traitement tenseur.
Au cours des quatre dernières années, l'équipe NVIDIA Applied Deep Learning Research a travaillé sur un projet de génération d'images, combinant le DLSS avec une technique d'estimation du flux optique. Le but était de parvenir à un résultat visuellement satisfaisant, d'insertion d'images précises entre des images existantes, afin d'améliorer l'expérience de jeu en la rendant plus fluide. L'estimation du flux optique, est couramment utilisée pour mesurer la direction et l'amplitude du mouvement apparent des pixels, entre des images graphiques ou des images vidéo rendues consécutivement. Dans les domaines des graphiques et de la vidéo 3D, les cas d'utilisation typiques incluent la réduction de la latence dans la réalité augmentée et virtuelle, l'amélioration de la fluidité de la lecture vidéo, l'amélioration de l'efficacité de la compression vidéo et la stabilisation de la caméra vidéo. Les utilisations via Deep Learning, incluent souvent la navigation automobile et robotique, ainsi que l'analyse et l'identification vidéo.
Le flux optique est plutôt similaire au composant d'estimation de mouvement utilisé en encodage vidéo, mais avec des exigences bien plus élevées en matière de précision et de cohérence. En conséquence, différents algorithmes sont utilisés. Depuis la microarchitecture Turing, les GPU du caméléon intègre un moteur de flux optique autonome (OFA), c'est à dire fonctionnant de manière indépendante des Cuda Core. Cette unité OFA est capable de fournir jusqu'à 300 TeraOPS (TOPS) de travail sur le flux optique (plus de 2 fois plus rapide que l'OFA de génération Ampère). Et c'est la que l'on en revient aux recherches de l'équipe mentionnée au paragraphe précédent, qui aboutissent à la création du DLSS 3, qui va en fait coupler le DLSS 2.0 utilisant l'inférence pour reconstituer une image en haute définition depuis une définition plus basse, à l'insertion d'images générées depuis les données issus de l'OFA. Plus de détail à ce sujet dans la page dédiée.

Voilà, c'est tout pour la partie architecture d'Ada Lovelace, nous vous proposons page suivante, de découvrir la mise en œuvre de cette dernière et le descriptif d'autres fonctionnalités.
|
|
| Un poil avant ?La relève NUC Extreme chez Intel sera encore moins mini-PC-esque qu'avant | Un peu plus tard ...L'Unreal Engine 5.1 plus très loin de débarquer | |





















