Hard du hard • Ça fonctionne comment, un processeur ? (Partie 2) |
• 16 Avril 2018



Lorsqu'on pense à un CPU, on pense souvent "calcul". Or il s'avère que les opérations coûteuses en temps sont plutôt les chargements mémoire. Bien que l'Out-of-Order permette de masquer ce temps par du temps de calcul, cela n'est pas suffisant. Selon l'application, un processeur peut passer entre 10 et 33% de son temps à "attendre". Certaines améliorations ont vu le jour bien avant, dès les 80486 d'Intel (1989) où le but était simplement d'accélérer les temps de chargement mémoire.
Vous avez sûrement déjà vu sur les caractéristiques des différentes puces la quantité de cache, par exemple 24,75 Mo sur un i9-7980XE. Le principe du cache est de proposer une mémoire "tampon" dans laquelle sont stockées les dernières variables utilisées. Il en existe différents niveaux, allant du L1 au L3 ; les i5-5675C et i7-5775C étant les seuls à avoir proposé au grand public sur plateforme desktop un cache "L4" via de la eDRAM embarquée. Dans le même esprit, les CPU professionnels, par exemple les Xeons Phi, sont équipés d'HBM pour implémenter le niveau L4.
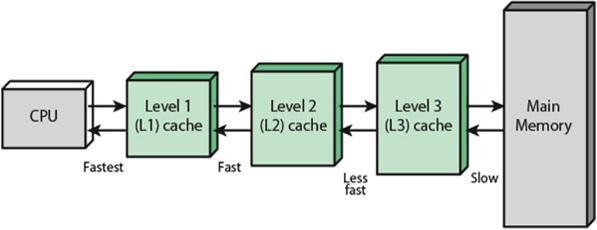
Plus le numéro du cache est élevé, plus il est "loin" du processeur : le CPU met ainsi plus de cycles à charger la valeur, mais le cache est de plus grande taille. Le cache L1 est souvent séparé en L1-D et L1-I ; le premier contenant des données et le second les instructions suivantes à exécuter (et oui, elles sont bien en mémoire elles aussi !).
| Nom | Temps d'accès (cycle CPU) | Latence (nanosecondes) | TAILLE |
|---|---|---|---|
| L1 | 4 | 1-2 | 64 ko |
| L2 | 12 | 3-5 | 256 ko |
| L3 | 44 | 20-40 | 2 Mo/cœur |
| RAM | 150 | >100 | >4 Go |
Temps d'accès pour un i7-6700
On accède au cache par ligne de cache, un bloc contiguë de, en général, 64 octets. Cela signifie que même si votre variable est stockée sur 8 bits, au-moins l'intégralité des 64 octets adjacents (le décalage étant choisi pour s'aligner sur le plus petit multiple de 64 proche) est rapatrié depuis la RAM. Si le cache L1 et L2 est la plupart du temps propre à un cœur ; le L3 est par contre souvent partagé.
Les caches peuvent être inclusifs ou exclusifs (est-ce que le L1 est contenu dans le L2 ?), write-back ou write-through (quand mettre à jour la valeur en RAM, au chargement où à l'écriture ?), et être de type victime (le L2 contient les données qui débordes du L1) ou non (en chargeant une variable, on charge les pages mémoires adjacentes dans le L2. Si le type victime est empiriquement moins performant, son implémentation est bien plus simple en pratique.
Dans le cas de système multicœurs, il faut préserver la cohérence des caches : c'est-à-dire le fait qu'une variable puisse être modifiée dans le cache du cœurs 0,de manière visible par tous les autres cœurs : il faut alors invalider les lignes de cache possédant l'ancienne valeur, ce qui peut être très coûteux en performance. Différents protocoles existent pour cela, attribuant à chaque lignes de cache un état, par exemple MOESI (Modified, Owned, Exclusive, Shared et Invalid).
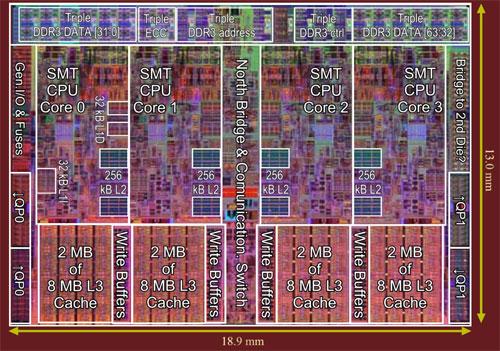
L'organisation des caches sous Nehalem : 2x 32 Ko de L1 et 256 Ko de L2 par cœur, et 8 Mo de L3 partagés entre les 4 cœurs (crédits : Chip Architect)
Une dernière notion sur le cache est l'associativité : si n'importe quelle endroit de la mémoire peut être mis en cache sur n'importe quel endroit du cache, ce dernier est dit complètement associatif (fully associative). Si chaque zone mémoire peut être chargée à un unique endroit du cache, on parle de cache non associatif. Enfin, un cache associatif à N voies (N entier, généralement entre 2 et 8) est un cache divisé en N parties non associatives mappées sur les mêmes zones mémoires. Ainsi, si plusieurs zones correspondant à la zone en cache doivent être chargée simultanéement, chacune est mise dans une division différente du cache au lieu d'écraser tour à tour la valeur précédente. Pas facile de comprendre cela sans schéma !
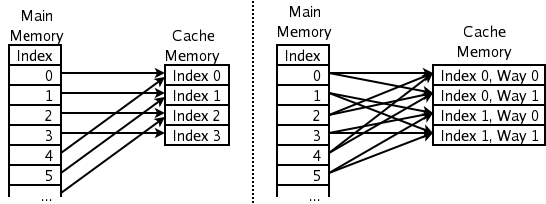
Cache non associatif (à gauche) contre 2-associatif (à droite). Merci Wikipédia !
Un problème persiste lors de l'utilisation de cache : le premier accès doit toujours se faire en RAM, et donc être coûteux. Pour contrer cela, il existe des mécanisme de prefetching, qui consiste à charger préventivement certaines données dans le cache car le CPU devine les opérations suivantes. Cela est particulièrement efficace lors d'accès séquentiels : par exemple si vous accédez une à une à toutes les cases d'un grand tableau dans l'ordre croissant.
Pourquoi donc s'embêter avec des mécanismes aussi complexes ? Toujours la même raison : les performances. En effet, empiriquement, un cache associatif à deux voies correspond à peu près au performance d'un cache non associatif deux fois plus grand. Dans la même veine, un cache write-through est moins performant qu'un write-back, mais cela s'effectue au détriment de sa taille.
Des mémoires virtuelles
Pour diverses raisons, principalement pour faciliter la programmation et isoler la mémoire de chaque processus, les addresses manipulées par les programmes sont des addresses virtuelles. Elle ne correspondent en rien à la réalité physique, et c'est au MMU (Memory Management Unit), de faire la traduction des adresses virtuelles vers les adresses physiques, et vice-versa. Un cache est utilisé, une fois encore, pour accélerer le processus : le TLB (Translation Lookaside Buffer). Tout comme les lignes de cache, il existe une plus petite unité de mémoire virtuelle appelée page mémoire. Le TLB retient simplement les dernière traductions des pages récemment accédées afin de répondre le plus rapidement possible à une éventuelle future opération les concernant. Fait intéressant, ces pages mémoire ne sont pas réservées à l'allocation de la mémoire (applel de malloc() en C) mais à la première écriture dans la page (*pointeur = ...). Cela entraîne des comportement tels que celui de la librarie OpenCL Linux, qui réserve d'emblée 12 à 16 Go de mémoire lors de son exécution quelle que soit la charge de travail demandée ! Lorsqu'une page demandée n'est pas attribuée, une page fault a lieu (erreur bénigne) entraînant soit une segmentation fault (le programme n'avait pas le droit d'y accéder) ou la création effective de la page.
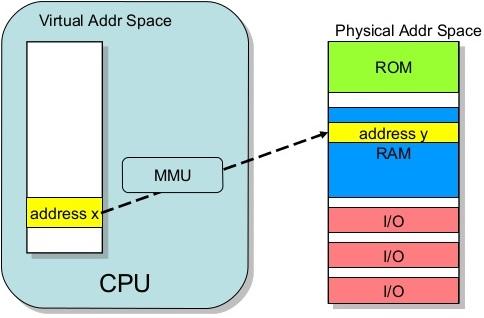
L'adressage virtuel est converti en adressage physique. Notons que certaines zones RAM sont réservées au système d'exploitation !
L'attaque Meltdown consiste à demander un accès en lecture à une page mémoire appartenant normalement au noyau, puis à charger dans un autre registre une adresse dépendante du premier résultat. L'erreur attendue (la page mémoire du noyau n'est pas accessible) a bien lieu, et le second registre ne contient aucune information compromettante. Sauf que le second chargement est effectué préventivement, et donc l'adresse de la page noyau est stockée quelque part : dans le cache ! Cependant les données ne sont toujours pas accessibles : il faut en fait charger une donnée dans une ligne de cache dépendant de sa valeur, et par un truchement de temps d'accès, remonter à la valeur originale (utilisation d'un side chanel). Le patch correctif consiste en la séparation des pages du noyau et des processus (alors qu'auparavant les pages noyaux étaient simplement marquées comme inaccessibles), ce qui engendre un surcoût à chaque appel du kernel, phénomène qui se produit lors des lectures/écritures sur disque par exemple.
Pour Spectre, l'histoire est plus complexe. La première variante de spectre consiste à imbriquer le chargement illicite dans un if(condition) {attaque meltdown}. Comme les CPU sont équippés d'un prédicteurs de branchement, il est possible de forcer une fausse prédiction (la condition est fausse mais l'attaques est exécutée spéculativement) ; et ainsi forcer le chargement d'une adresse mémoire protégée (par exemple celui d'un autre processus....) selon le même principe que l'attaque précédente.
La seconde variante est encore plus retorse : certaines instructions permettent de lancer l'exécution d'une fonction à une adresse stockée en mémoire. Tout comme la première variante, il faut entrainer le prédicteur de branchement afin de le pousser à l'exécution spéculative du code malicieux de Meltdown, puis lancer l'exécution spéculative de la fonction pirate, et récupérer dans le cache les traces laissées.
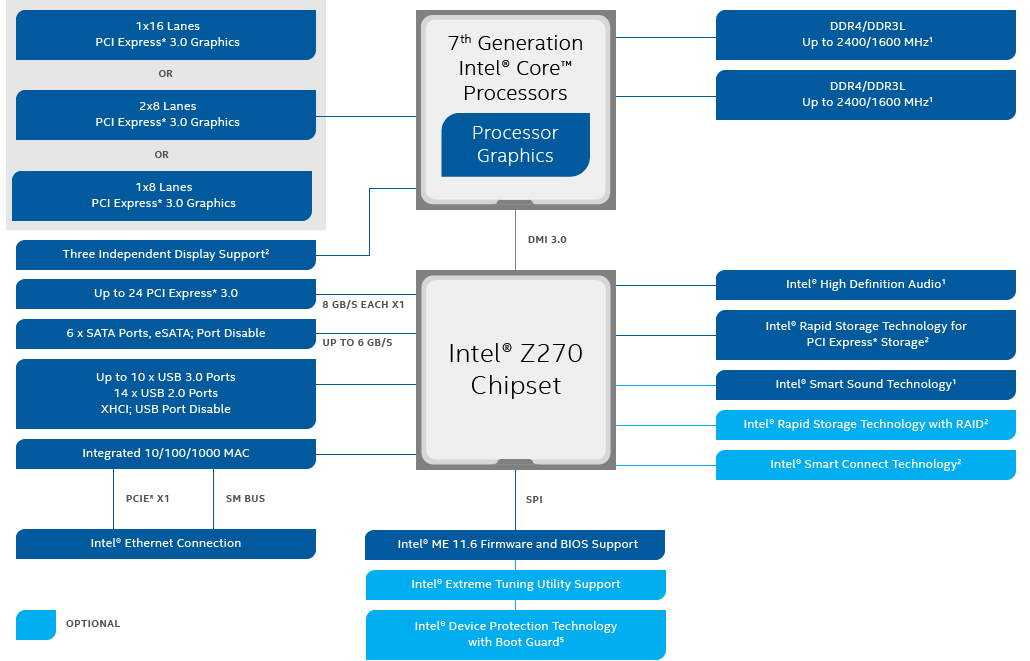
Oui et non ! Jusque Nehalem (non inclus), les CPU Intel ne possédaient pas de contrôleur mémoire : ce dernier était intégré à la carte mère, dans un composant appelé northbridge. En bon français pont nord, il permettait également de gérer le PCI-e et, en son temps, l'AGP. Qui dit pont nord dit pont sud, ou southbridge : relié au northbridge, son rôle était d'interfacer les autres connectiques : PCI, port ISA, USB, liaison avec le BIOS... Ce n'est plus le cas désormais. Dans les processeurs modernes, tous ces contrôleurs sont intégrés, et les "chipset" est une simple puce permettant ou non l'overclocking et redirigeant les lignes PCI-e sortant du CPU vers différentes connectiques soigneusement choisies par le constructeur.
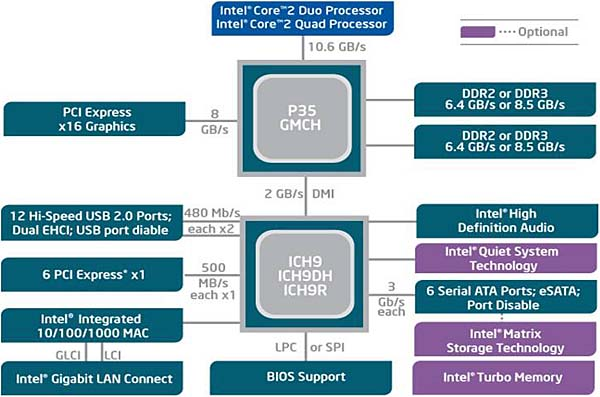
Le vieux chipset P35 (Core 2 Quad) : northbridge et southbridge
![Le courageux Z270 en détail [cliquer pour agrandir]](/images/stories/articles/cpu/archi-cpu/z270-chipset-block-diagram_t.png "Visionner en grand sur un magnifique pop-up")
Le plus récent Z270 : un seul chipset et beaucoup de gestion directe par le CPU !
L'effet NUCA est très similaire à l'effet NUMA, qui s'est vu principalement sur les serveurs. Le problème s'est vu lorsque les cartes mère ont eu plusieurs sockets, chacune reliée à ses barettes de RAM. De manière logique, les données présentes dans la RAM liée au CPU 1 doivent pouvoir être accessibles par le CPU 2. Pas besoin de vous faire un dessin, ces variables-là mettrons plus de temps à arriver. C'est ce qui est appelé effet NUMA : Non-Unifom Memory Access. Le même phénomène transposé aux caches est appelé NUCA, on vous laisse deviner pourquoi ! Il faut donc que le système choisisse précautionneusement la localité physique des variables afin d'éviter au maximum les surcoûts d'accès distant, et éventuellement les déplacer en fonction des cœurs les utilisant. D'un point de vu théorique, ce problème est intrinsèquement difficile : quel que soit l'heuristique de placement choisie, il existera toujours un cas qui mettra en difficulté le CPU. En pratique c'est un peu moins vrai : tant que les données sont utilisées par un même processus, l'OS est assez intelligent pour les conserver près du cœurs l'exécutant.
![Photo du die Zepplin de chez Amédé [cliquer pour agrandir]](/images/stories/articles/cpu/archi-cpu/amd-ryzen-zepplin_t.jpg "Cliquédélique !")
Le fameux die Zepplin, avec ses deux CCX de part et d'autre
Pour le moment, seul Ryzen pose ce problème au grand public. En effet, les R3/R5/R7 sont construits sur le même die, Zepplin. Et ce Zepplin est composé de 2 CCX, un bloc de quatre cœurs contenant un unique L3. Comme nous l'avons vu, il est nécessaire de synchroniser ce L3 entre tous les cœurs. Pour ce faire, AMD a développé une solution personalisée... L'Infinity Fabric ! Reposant sur une interface 256 bits bi-directionnelle, c'est elle qui se charge de la cohérence inter-CCX. Le temps nous a révélé que celle-ci fonctionne à la même vitesse que le contrôleur mémoire : en augmentant la vitesse de la RAM, on augmente la vitesse de communication interprocessus et donc la vitesse des programmes utilisant plusieurs cœurs situés sur les CCX différents. Bien sur, l'ordonnanceur peut être modifié pour privilégier les cœurs d'un CCX pour un même programme, mais cela n'est pas toujours possible.
Ce phénomène est encore amplifié sur Threadripper (et EPYC), car ce dernier possède deux (respectivemenbt quatre) dies distincts : le surcoût liée à l'accès d'une variable dans un cache distant et donc d'autant plus important. Dans un utilisation de type gaming, où le nombre important de cœurs est encore peu utilisé, cela se ressent d'autant plus. Par contre, pour de la compilation, du rendu ou de l'encodage, chaque cœur ne touche que ses propres données, d'où des performances optimales.
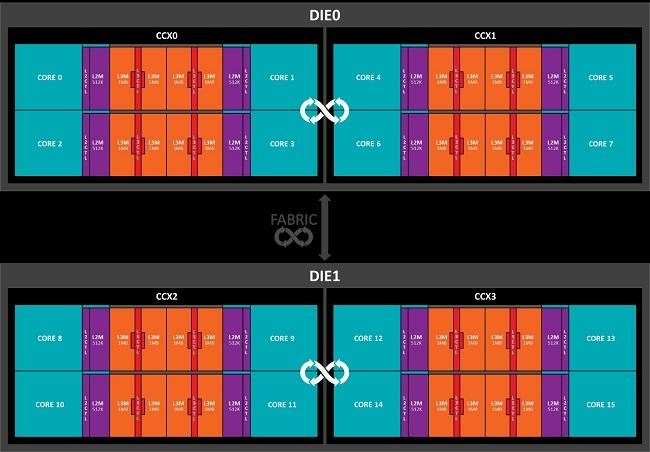
Les 2 dies de Threadripper à 2 CCX chacuns
|
|
| Un poil avant ?AMD sur un projet GPU Zen ? | Un peu plus tard ...Kezako ce Core i7-8086K ? | |
| 1 • Préambule |
| 2 • Plus de cœurs, plus de foi ! |
| 3 • |
| 4 • Grenier, le futur ! |