Test • NVIDIA GeFORCE RTX 2080 / 2080 Ti |
• 19 Septembre 2018



Test • NVIDIA GeFORCE RTX 2080 / 2080 Ti |
• 19 Septembre 2018
Pour ceux intéressés par l'architecture Turing, nous vous invitons à lire le dossier que nous lui avons consacré il y a quelques jours. Résumée en quelques lignes, cette dernière ressemble beaucoup à Volta avec quelques ajouts. Par rapport à Pascal (gaming) : des caches plus gros et rapides, des SM "plus petits" mais plus nombreux et capables de traiter en parallèle les calculs sur entier ou en virgule flottante (y compris en demi-précision (FP16) à double vitesse). Ces derniers intègrent à présent des Tensor Cores, accélérant significativement les calculs liés à l'intelligence artificielle, en particulier l'inférence, ainsi que les RT Cores, pierre angulaire de l'accélération matérielle du Ray Tracing, utilisable en temps réel dans les jeux via un rendu hybride, mixant cette technique à la rastérisation.
![Turing en chiffres [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/turing_t.jpg "La magie de la loupe, sans loupe")
Turing en chiffres dans la déclinaison dédiée à la RTX 2080 Ti
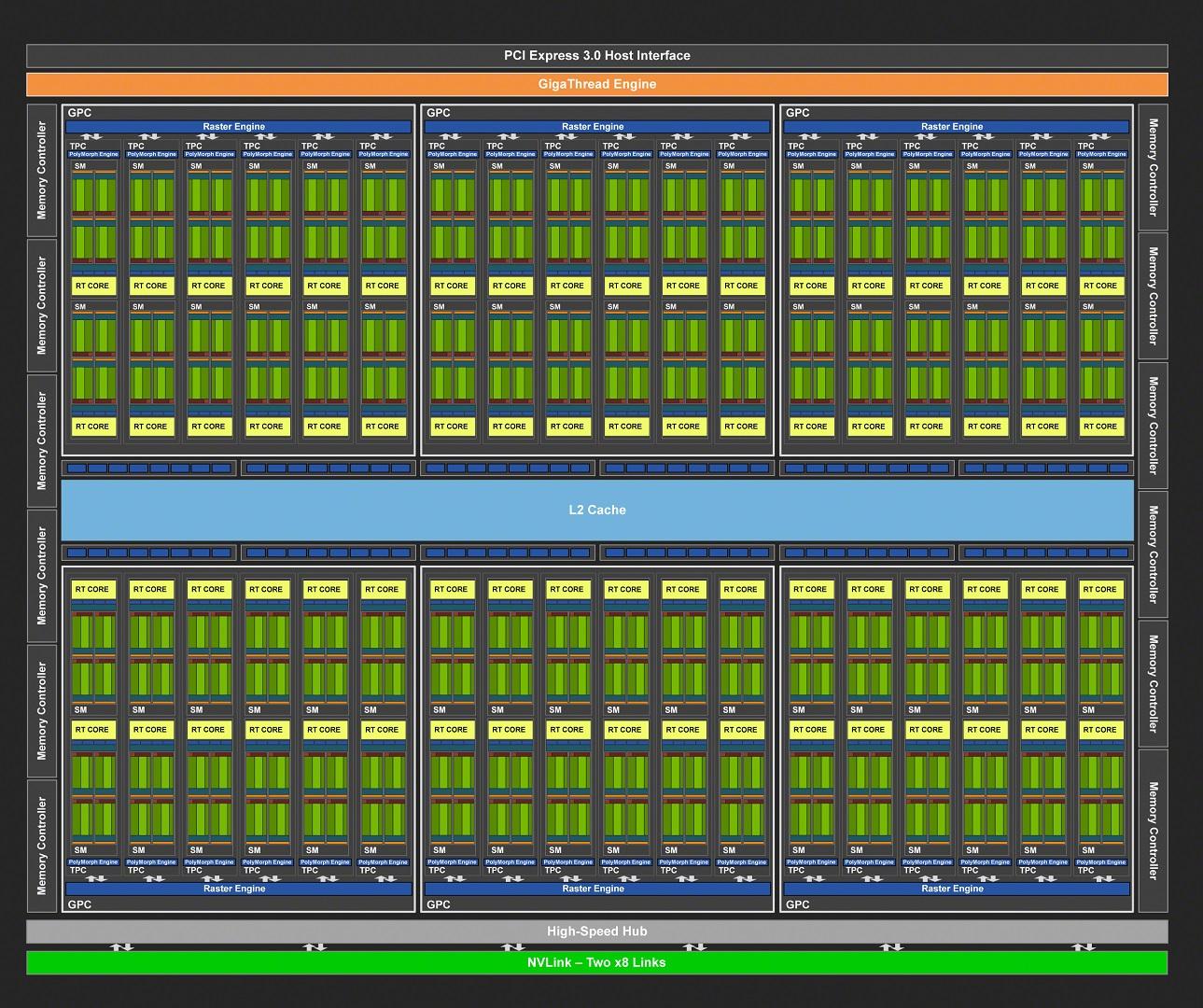
NVIDIA a conçu à partir de cette architecture 3 GPU, nous ne nous intéresserons qu'aux deux plus performants aujourd'hui. Le plus gros de la famille est le TU102, qui utilise un die 60% plus grand que GP102 à 754 mm² et intégrant pas moins de 18,6 milliards de transistors. Compte tenu du coût de production d'une telle puce, celles "parfaites" sont réservées pour le moment aux très onéreuses Quadro RTX 6000/8000. Le diagramme de la puce complète, ci-dessous, indique la présence de 6 GPC, chacun comprenant 6 TPC, conduisant à un total à 72 SM. Cela correspond à 4608 unités de calcul, 288 TMU, 576 Tensors Cores et 72 RT Cores. À cela s'ajoute 12 contrôleurs mémoire 32-bit, 96 ROP, 6 Mo de cache L2 et 2 liens NVLink 8x pour permettre un SLi avec une bande passante cumulée de 100 Go/s.
![Diagramme TU102 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tu102_diagram_t.jpg "Même pas cap' de cliquer")
Pour la RTX 2080 Ti, NVIDIA utilise un GPU partiellement activé, afin de faciliter sa production et réduire ainsi les coûts, puisque les puces dont certaines unités sont défectueuses restent utilisables, et améliorent ainsi les rendements de production. Voici les caractéristiques principales de cette variante de TU102, résumées dans le tableau ci-dessous.
| GeForce RTX 2080 Ti | Quantité activée |
|---|---|
| GPC | 6 |
| TPC / SM | 34 / 68 |
| CUDA Cores | 4352 |
| TMU | 272 |
| Tensor Cores | 544 |
| RT Cores | 68 |
| ROP | 88 |
| L2 (Mo) | 5,5 |
| Bus mémoire (bits) | 352 |
Intéressons-nous à présent à TU104, qui prend place au sein de la RTX 2080. Première constatation, il n'est pas composé de 4 GPC comme c'est traditionnellement le cas sur cette gamme de GPU, mais de 6 à l'instar des GP102/TU102. Il gagne ainsi 2 Raster Engine, de quoi afficher jusqu'à 6 triangles par cycle. Il a toutefois subit une cure d'amincissement, puisque chaque GPC ne contient plus "que" 4 TPC / 8 SM, soit 33% de moins que son grand frère. Il en est de même pour les contrôleurs mémoire, ROP et cache L2. Du côté comptable, le GPU embarque un bus mémoire à 256-bit, 64 ROP, 48 SM, ce qui conduit à 3072 CUDA Cores, 192 TMU, 384 Tensor Cores et 48 RT Cores. Pour finir, il ne conserve qu'un seul lien NVLink 8x, sur les 2 que comptait TU102.
![Diagramme TU104 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/tu104_diagram_t.jpg "Ne pas appuyer ici")
À l'instar de la gamme supérieure, le GPU utilisé est quelque peu bridé pour faciliter sa production (545 mm² quand même, soit davantage qu'un GP102), avec un TPC inactif soit 46 SM activés, sur les 48 que compte la puce. Le bus mémoire et les éléments liés (ROP et L2), sont par contre conservés intégralement. Ci-dessous, le récapitulatif du GPU dans cette configuration.
| GeForce RTX 2080 | Quantité activée |
|---|---|
| GPC | 6 |
| TPC / SM | 23 / 46 |
| CUDA Cores | 2944 |
| TMU | 184 |
| Tensor Cores | 368 |
| RT Cores | 46 |
| ROP | 64 |
| L2 (Mo) | 4 |
| Bus mémoire (bits) | 256 |
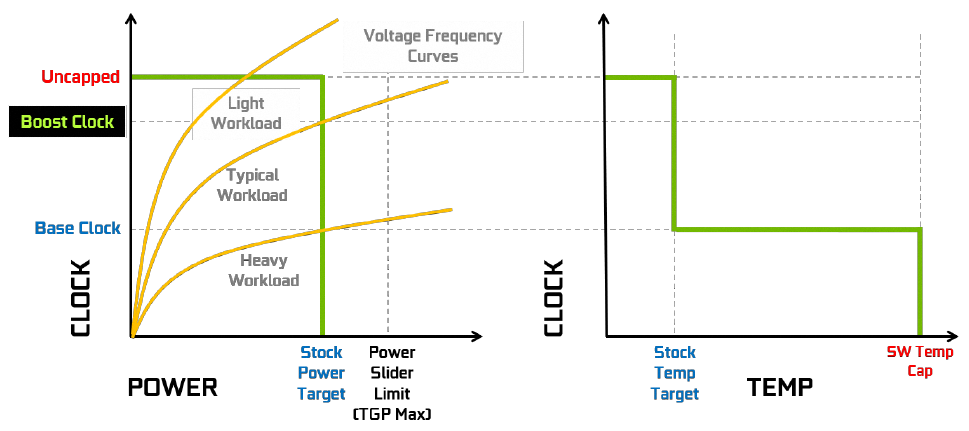
Avant d'attaquer la description de la carte testée en page suivante, un petit rappel sur un changement notable au niveau de la gestion des fréquences appliquées au processeur graphique via GPU Boost. Ce mécanisme a pour objectif de pousser chaque puce au plus près de ses limites, en s'affranchissant de tests trop sélectifs en sortie de production. C'est en effet GPU Boost qui est est chargé par la suite, de s'assurer que les conditions environnementales permettent au GPU de fonctionner de manière stable et sans risque. Pour ce faire, il impose un double carcan constitué d'une limite de consommation et de température selon l'itération. Avec la version 3 introduite lors du lancement de Pascal, à partir de 37°C et tous les 5°C supplémentaires, le GPU perd 1 bin (~13 MHz) et ce jusqu'à la consigne de température maximale. Il perd alors autant de bins que nécessaire pour rester sous celle-ci.
La fréquence progressant de concert avec la tension d'alimentation du GPU, c'est un moyen très efficace pour contrôler la consommation (qui évolue au carré de la tension et dispose aussi de sa propre limite), évitant ainsi une envolée des nuisances sonores, avec un refroidisseur pas forcément dimensionné pour la dissiper discrètement, ce qui est le cas des Founders Edition à turbine. Le souci d'une telle approche, est la pénalisation de toutes les cartes Pascal, y compris les customs des constructeurs tiers, avec des refroidisseurs surdimensionnés. En effet, NVIDIA autorise la modification du TDP max. des cartes, mais en aucun cas les paliers de température par défaut de GPU Boost 3.0. Ci-dessous une représentation graphique de ce fonctionnement.
![GPU Boost 3.0 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gpuboost3_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
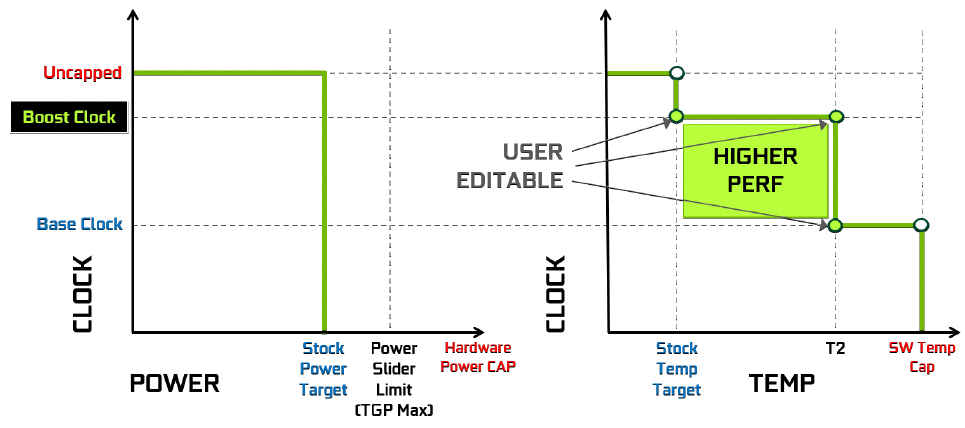
Avec Turing, NVIDIA a annoncé GPU Boost 4.0. En gros, ce dernier fonctionnerait de manière similaire, mais avec un ajustement qui fait toute la différence. En effet, les valeurs de températures sont à présent exposées et il possible de les modifier. Bien sûr, il est nécessaire de rester dans la plage autorisée par le caméléon, mais le seuil à 37°C qui marquait le "début de la baisse" des fréquences, n'est plus imposé. Cela coïncide avec l’utilisation d'un refroidisseur plus performant sur les Founders Edition, qui ne perdent donc plus de fréquence du fait de la température. Toujours est-il, qu'il était très difficile de s'approcher du TDP max sur ces dernières en version Pascal, à part lors des premiers instants de forte sollicitation, ce ne sera plus le cas avec les versions Turing, qui seront davantage limitées par leur enveloppe thermique. Ci-dessous, la représentation schématique de GPU Boost 4.0. Notons également qu'un bin prend à présent la valeur de 15 MHz, contre 13 MHz auparavant.
![GPU Boost 4.0 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gpuboost4_t.png "Si vous cliquez, vous cliquez.")
Voilà pour le sujet, passons page suivante à la description des cartes lancées par le caméléon.
|
|
| Un poil avant ?Live Twitch • Une quête avec des trolls poilus dedans ! | Un peu plus tard ...Le chipset Z390 (ré)officialisé le 8 octobre ? | |