Test • GeFORCE GTX 1070 & 1080 |
• 21 Juin 2016



Test • GeFORCE GTX 1070 & 1080 |
• 21 Juin 2016

Pour concevoir son nouveau GP104, NVIDIA s'appuie donc sur sa dernière architecture Pascal. Toutefois, cette dernière qui a été inaugurée au travers du GP100, une puce monstrueuse de 610 mm² que l'on retrouve au sein de la gamme Tesla dédiée au GPU Computing, diffère justement entre les 2 GPU. Nous préciserons ce point au cours de cette page. Elle succède donc à Maxwell et Kepler, elles-mêmes fortement basées sur Fermi qui a posé les fondations des puces modernes du caméléon. Si vous n'êtes pas au fait de ces architectures, nous vous invitons à relire ce dossier par exemple pour en comprendre les grands principes. Ainsi, GP104 s'appuie toujours sur des unités polyvalentes nommées Streaming Multiprocessor ou SM pour les intimes. Mais avant de détailler tout cela, commençons par le traditionnel diagramme GPU d'un point de vue macroscopique :
![diagram gp104 t [cliquer pour agrandir]](/images/stories/articles/gpu/gtx1070_1080/images/diagram_gp104_t.png "Ne pas appuyer ici")
Diagramme logique du GP104 - Cliquer pour agrandir
Ces SM sont regroupés au sein des GPC (Graphics Processor Cluster) qui intègrent également un Raster Engine ou moteur de rastérisation, chargé de découper les triangles en pixels. Mais la subtilité provient à présent de l'apparition de TPC pour Texture Processor Cluster. Kesako ? Le nom est trompeur puisqu'il s'agit en fait de la structure regroupant SM et Polymorph Engine, c'est-à-dire les unités dédiées à la géométrie et que le caméléon décrivait précédemment comme faisant partie intégrante des SM. C'était donc une simplification adoptée lors des représentations schématiques, puisqu'il n'y avait à chaque fois qu'un SM par TPC. Ce n'est plus forcément le cas avec Pascal puisque le GP100 en propose 2 par TPC, c'est d'ailleurs une des différences avec GP104 qui reste lui à la valeur 1. Si le nombre de GPC n'évolue pas (toujours 4) entre GM204 et GP104, leur composition diffère avec cette fois 5 TPC (contre 4 précédemment), portant ainsi le nombre total de SM à 20 pour le GPU complet. Avant de détailler ces derniers, jetons un coup d'oeil au sous-système mémoire.
Le bus mémoire reste inchangé à 256-bit puisque toujours constitué de 8 contrôleurs 32-bit, le cache L2 associé à chacun d'entre eux est également le même (256 Ko) soit un total de 2 Mo pour le GPU. Par contre, le caméléon ne se contente pas d'associer de la GDDR5 à ces contrôleurs, mais également, et pour la première fois sur une carte graphique, de la GDDR5X. Cette dernière adopte un fonctionnement QDR (Quad Data Rate) qui permet de doubler la bande passante à fréquence équivalente. La consomamtion est donc mécaniquement en baisse, par contre cela implique un prefetch doublé à 16n et des accès en 512-bit, ce qui ne pose pas de problème particulier aux GPU friands avant tout de bande passante.

Les première puces GDDR5X sont certifiées à 10 Gbps soit +25% par rapport aux meilleures GDDR5, mais NVIDIA ne s'est pas contenté de ce point et indique avoir retravaillé ses algorithmes de compression (sans perte) des couleurs afin de réduire les besoins en bande passante mémoire. C'est en particulier le cas de la technique Delta Color, qui permet de calculer l'écart entre 2 couleurs sur des pixels adjacents plutôt que de coder indépendamment chaque couleur de pixel, ce qui peut être très bénéfique si les couleurs sont proches.

La compression Delta Color
Ces algorithmes implémentés depuis Fermi, en sont donc à leur quatrième révision qui permet de proposer davantage de choix de calculs Delta au "compresseur". Afin de mettre en avant les progrès liés à cette nouvelle itération, ;NVIDIA propose les 3 clichés ci-dessous représentant les images tirées de Project CARS sans compression, avec la compression induite par les puces de génération Maxwell et enfin celle de la génération Pascal :

Exemples de mise en oeuvre Delta Color : A gauche sans compression, au milieu avec Maxwell et à droite Pascal
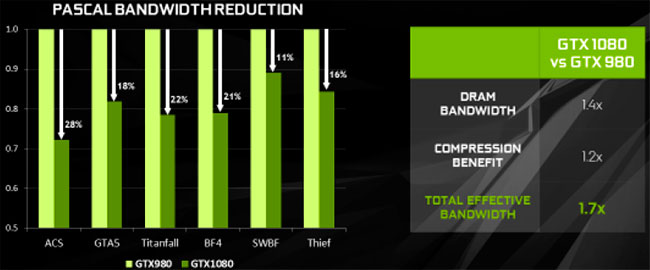
Au final avec l'accroissement de l'efficacité des divers algorithmes de compression couleur, NVIDIA annonce une augmentation de 20% de la bande passante effective du GP104 par rapport au GM204. Si l'on combine cet effet aux gains liés cette fois à l'emploi de GDDR5X, on parvient à une augmentation de 70% de la bande passante effective !
Avant d'attaquer en détail l'évolution des SM, un dernier mot pour préciser que le nombre de ROP (vous savez, les petites bêtes chargées d'écrire en mémoire) n'évolue pas par rapport au GM204, toutefois ces derniers pourront profiter à l'instar du reste du GPU de l'augmentation de fréquence rendu possible par le nouveau procédé de gravure 16nm FinFET+ de TSMC. Voyons à présent ce qu'ils ont dans le ventre ces fameux SM :
Un SM, au coeur de Pascal
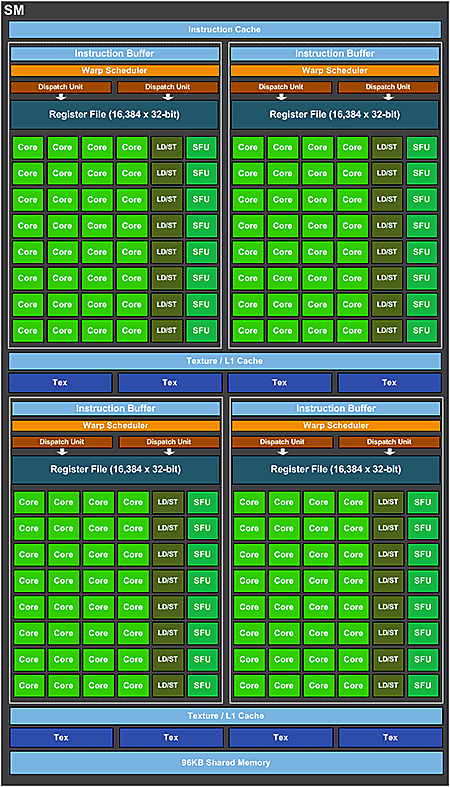
Si on exclut le fait que le Polymorph Engine (qui passe en version 4.0) n'en fasse plus partie (ce qui n'a jamais été vraiment le cas en réalité, sic), les SM du GP104 ressemblent comme 2 gouttes à ceux du GM204. On retrouve donc les 128 unités de calcul simple précision couplées à 32 unités de calcul SFU pour les opérations spéciales. N'apparaissent pas sur le schéma, mais sont bien présentes 2 unités de calcul en double précision (64-bit) pour assurer la compatibilité. Le GP100 diffère justement à ce niveau puisqu'il propose par SM, 64 unités de calcul SP et 32 unités DP. Côté TMU ou unités de texturing, pas de changement non plus puisque l'on reste à l'instar de Maxwell à 8 par SM.
La hiérarchie mémoire au sein du SM est également identique, tout du moins entre GM204 et GP104 avec 96 ko intégralement dédiés à la mémoire partagée et le cache L1 à 24 Ko. Le GP100 voit de son côté la mémoire partagée progresser à 128 Ko. Au final, les unités de calcul SP passent de 2048 sur GM204 à 2560 sur GP104, quant aux TMU, elles suivent la même inflation en passant de 128 à 160. Pascal dans sa version GP104 est donc très proche d'un GM204 qui aurait subit une inflation de 25% des unités de Calcul et de texturing. Tout cela nous donne un joli bébé de 7,2 milliards de transistors pour 314 mm² gravé en 16nm. GK104 gravé en 28nm se contentait lui de 3,54 milliards pour 294 mm² alors que GM204 avait connu de son côté une inflation notable avec 398mm² toujours en 28nm et près de 5,2 milliards de transistors. NVIDIA a donc fait le choix de revenir à une taille de die proche des 300 mm² pour cette gamme de puces. Face à la concurrence, la superficie de GP104 le situe en deçà de Tonga (5 milliards de transistors / 368 mm²) en attendant Polaris gravée en 14 nm et annoncée bien plus petite (~230mm²).

On le voit donc clairement, le nouveau procédé de gravure permet de faire exploser le nombre de transistors par mm². La stagnation de ces process dans le domaine GPU a contrarié les deux géants du secteur qui s'y sont adaptés avec plus ou moins de succès. La nouveauté cette année en sus de l'abaissement de la finesse en elle-même, c'est le choix entre deux acteurs : TSMC propose du 16nm qui permet grosso modo de doubler la densité et un gain de fréquence important du fait d'une conception 3D des transistors (FinFET). Samsung est le second acteur avec son process 14nm (FinFET également) à priori 9% plus dense (si on se base sur les puces Apple A9 produites via les deux fondeurs) et disponible en deux versions : LPE (Low Power Early) et LPP (Low Power Plus), la seconde permettant d'atteindre des fréquences 15% plus élevées associées à une consommation en baisse de 15%. C'est cette version licenciée à Global Foundries qui sera utilisée par AMD, NVIDIA ayant choisi TSMC.
Cette variable supplémentaire peut-être un facteur de réussite ou d'échec des stratégies respectives, mais aussi de placement des puces. Il est difficile de déterminer à l'heure actuelle quel est le meilleur choix : il semble que le 14 nm donne un petit avantage à AMD en termes de densité, donc de taille des die pour un même nombre de transistors et en conséquence de leur nombre sur un Wafer (disque de silicium sur lequel sont gravés les puces) déterminant le coût unitaire d'un GPU.
Mais ce n'est pas si simple : les Yield (rendement de puces fonctionnelles aux spécifications demandées), le coût de production (NVIDIA étant un plus gros client il peut probablement obtenir des tarifs potentiellement plus intéressants) et la performance du process (montée en fréquence, consommation, etc.) peuvent nuancer très largement cette première assertion. Ce qui est sûr c'est que le caméléon a souhaité profiter du passage au 16nm FinFET+ pour pousser largement les fréquences de son GP104, avec succès comme nous le verrons dans quelques pages. Cette stratégie peut être payante puisqu'un avantage de 30% en termes de fréquence face au concurrent permet un gain du même ordre au niveau des performances sans avoir besoin d'élargir la puce et donc augmenter les coûts. Wait & see donc.
Passons à présent aux diverses nouveautés apportées par cette génération Pascal en page suivante.
|
|





















