Test • nVIDIA GeFORCE GTX465/470/480 |
• 31 Mai 2010



Test • nVIDIA GeFORCE GTX465/470/480 |
• 31 Mai 2010
Pourquoi une telle attente me direz-vous ? En fait une combinaison de raisons explique cela. D'une part le procédé de gravure retenu pour ce nouveau GPU est le tant décrié 40 nm de TSMC. Si vous lisez régulièrement CDH, vous n'avez pas pu échapper aux news récurrentes traitant de la difficulté du fondeur à maitriser cette finesse de gravure, cela a eu pour conséquence un approvisionnement difficile des RADEON dans les premiers mois de leur commercialisation et ce phénomène se retrouve (amplifié) pour le GF100, puisque c'est son nom.
D'autre part, et aggravant le problème décrit précédemment, la complexité de la puce explique le retard. Imaginez donc : 3.2 Milliards de transistors constituent ce GF100, un record, mais aussi un sacré challenge pour TSMC dont il s'acquitte tant bien que mal vu les soucis déjà rencontrés pour son procédé de gravure 40 nm avec des puces nettement moins complexes. L'utilisation de ce dernier permet toutefois d'obtenir une puce légèrement plus petite (un peu plus de 500 mm² contre un peu moins de 600 mm²) que le GT200 originel qui utilisait, lui, la gravure 65nm pour ses 1,4 Milliards de transistors. AMD dispose par contre d'un gros avantage en terme de taille de puce et donc de coût de production avec son Cypress/RV870 (334 mm²) employant 2,15 milliards de transistors et animant ses cartes haut de gamme. Pour le fun, une petite vue sur la star du jour, mister GF100 dans toute sa splendeur :

Die GF100
Mais pourquoi est-il si méchant monstrueux ce GF100 ? Nous avions réalisé une preview de ce dernier lorsque nVIDIA avait communiqué à ce sujet pour masquer le manque concurrence face à AMD sur le front DX11, mais quelques rappels peuvent s'avérer utiles. Pour cela rien de tel qu'un beau diagramme comme les constructeurs les affectionnent tout particulièrement :
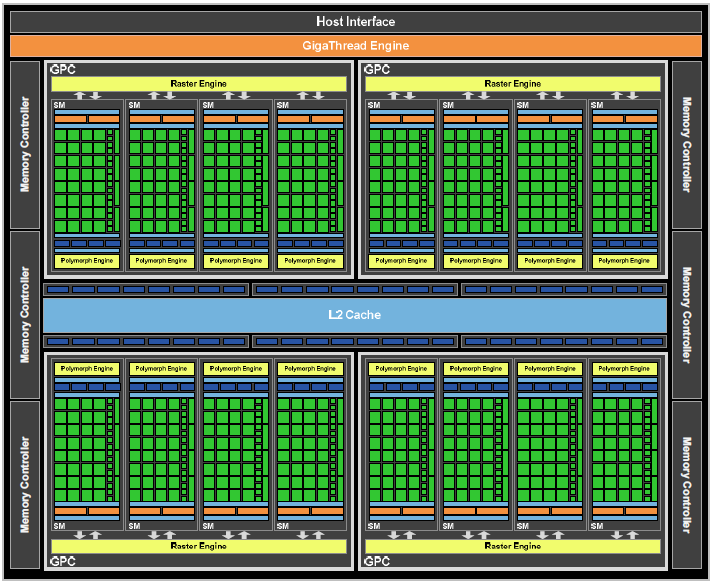
Diagramme GF100
En observant attentivement ce dernier on constate que le GF100 s'articule autour de 4 pavés autonomes au centre (les GPC pour Graphics Processing Cluster) autour desquels s'interconnectent des éléments partagés tels les contrôleurs mémoire et un cache L2. Intéressons-nous d'abord aux GPC dont les bases constituent un changement de philosophie dans l'approche de la structure de la puce par rapport aux G80/GT200 :
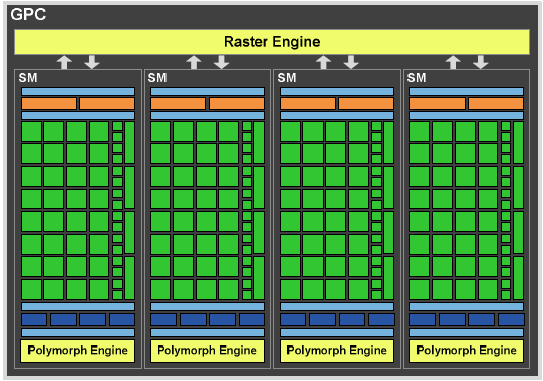
Diagramme GPC
En fait les GPC intègrent en leur sein des Streaming Multiprocessors que l'on connaissait auparavant sous le terme de multiprocesseurs mais largement retouchés par rapport à la génération précédente. Ainsi, le nombre d'unités de calcul (nommées Cuda Core par nVIDIA) passe à 32 par multiprocesseur, les registres sont doublés et on retrouve 4 unités (SFU) capables d'exécuter une opération complexe (cos, sin, etc.) par cycle. Afin que tout ce beau monde puisse être utilisé au maximum de ses possibilités, nVIDIA a doté ses SM de 2 scheduler assurant l'envoi de 16 instructions chacun.
Les unités de traitements géométriques prennent à présent en charge la tesselation, enfin, les unités de texturing répondent elles aussi aux nouvelles exigences de DX11 en termes de formats gérés (Gather 4). Changement notable également, elles sont à présent directement incluses dans le SM et sont au nombre de 4 par multiprocesseur. Si on fait les comptes, le GF100 comptant 16 SM on obtient un total théorique de 512 Cuda Cores et 64 unités de textures, cette dernière valeur étant en baisse par rapport aux 80 du GT200, l'optimisation des TMU et leur intégration directement aux SM étant censées compenser cela.
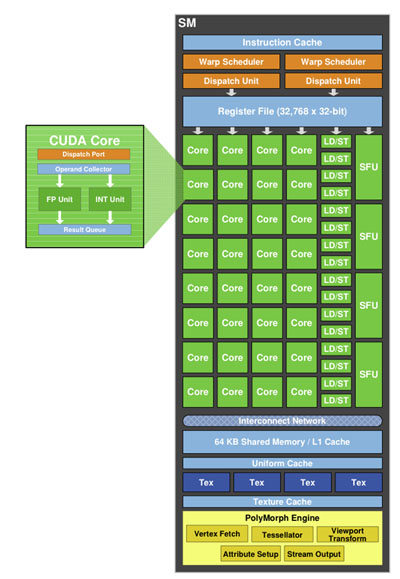
Diagramme SM
La pratique diffère aussi de la théorie et compte tenu des rendements actuels, les GPU les plus haut de gamme commercialisés ne disposent pas des 16 SM escomptés mais de 15 uniquement, ramenant les Cuda Cores à 480 et les TMU à 60. Intéressons-nous à présent à l'architecture mémoire du GF100. Toujours basé sur des contrôleurs 64 bits, leur nombre passe de 8 sur GT200 à 6 sur le GF100 soit un bus de "seulement" 384 bits contre 512 à son prédécesseur. Compensation, ils gèrent cette fois la GDDR5 et ses fréquences bien plus élevées permettent malgré l'amputation du bus une bande passante en hausse. Apparait également une organisation des caches à l'instar des CPU x86 avec à présent un L1 secondé par un L2 plus conséquent.
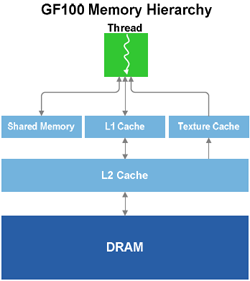
Hiérarchie mémoire GF100
Cette hiérarchie permet d'optimiser les accès selon les opérations à réaliser ce qui rend le GF100 beaucoup plus "élégant" que son prédécesseur à ce niveau avec le remplacement de nombreux caches spécifiques de petites tailles par une zone commune plus large. Pour finir sur l'architecture du GF100, un petit mot sur les ROP dont le nombre évolue pour passer de 32 à 48. Ces derniers sont également retouchés pour offrir entre autres choses un nouveau mode CSAA 32x. Cette augmentation du nombre est de bon augure quant à l'impact sur les performances du filtrage AA puisque l'on se souvient que le MSAA 8x était un des points faibles des G80/GT200.
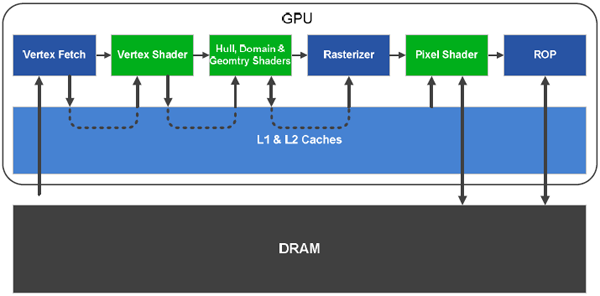
Fonctionnement cache GF100
C'est tout pour la théorie, en pratique nVIDIA a lancé à ce jour 3 cartes : la GTX 480 embarquant 480 unités de calcul, 60 TMU, 48 ROP, 1,5Go de GDDR5 en 384 bits, la GTX 470 embarquant elle 448 unités de calcul, 56 TMU, 40 ROP, 1,2Go de GDDR5 en 320 bits et la GTX 465 embarquant 352 unités de calcul, 44 TMU, 32 ROP et 1 Go de GDDR5 en 256 bits. Il est temps de détailler ces dernières page suivante.
|
|
| Un poil avant ?La HD5670 640SP face aux HD4830 et 4850 | Un peu plus tard ...Express • nVIDIA GeFORCE GTX 465 | |





















