Les R5 et R3 peuvent-ils être touchés par les limites du sous-système mémoire ? (MAJ) |
• 03 Mars 2017 à 08h58 • 19417 vues



Les R5 et R3 peuvent-ils être touchés par les limites du sous-système mémoire ? (MAJ) |
• 03 Mars 2017 à 08h58 • 19417 vues
Les tests de Ryzen sont sortis, pour ceux qui étaient équipés ou qui n'étaient pas en déplacement. Les résultats des benchmarks font ressortir plusieurs points. Ryzen est efficace en multitâche, bien meilleur en jeu que les FX, mais un cran en deçà des Intel, y compris ceux ayant 8 ou 10 coeurs avec lesquels ils se fritent. Ryzen souffre a priori de grosses latences mémoires, et même si les Aida64 et autres Sandra ne sont pas à jour sur ce point pour afficher des mesures précises, il y a un truc. HFR a poussé un peu plus loin que ceux qui en avaient fait le simple constat pour extraire plusieurs points d'explication.

Der8auer a délidé un R7 1700, puisque c'est le spécialiste, et cette manipulation n'est pas conseillée pour plusieurs raisons : la première est que l'IHS est soudé, la seconde est que les pins en dessous risquent de se tordre, et enfin l'utilisation de 2 joints en indium par AMD (youhou Intel, youhouuuu !) rend inutile la manoeuvre. Toutefois qui dit 2 modules oups CPU Complex (CCX), dit besoin de communication entre eux pour se répartir les tâches et le bus entre les 2 CCX ne permet que 22 Go/s, ce qui est très peu.
Il y a également le problème du cache L3. Chaque coeur CPU possède 2 Mo qui lui sont alloués, mais il peut piocher également dans le L3 des autres coeurs selon les besoins. Le souci provient de l'écart de latence nécessaire à cette opération, selon que le cache soit associé à un coeur faisant partie du même CCX (latence plus importante que le cache L3 alloué au coeur), ou d'un autre (latence encore plus élevée !). Comment se passe un accès mémoire cache sur un CCX ? Comme le rappelle AMD dans sa présentation du mois d'août, le L3 est de type L2 victime, c'est-à-dire qu'il sert de "poubelle" aux données non désirées par le L2. Le souci c'est que ce genre de gestion est moins efficace que les instructions ou demandes directes des coeurs, les données sont plus volatiles et augmentent les requêtes. Afin de proposer le moins possible ce cas de figure, AMD a été finalement obligé de doubler le L2 à 512ko contre 256ko aux Kaby Lake par exemple.
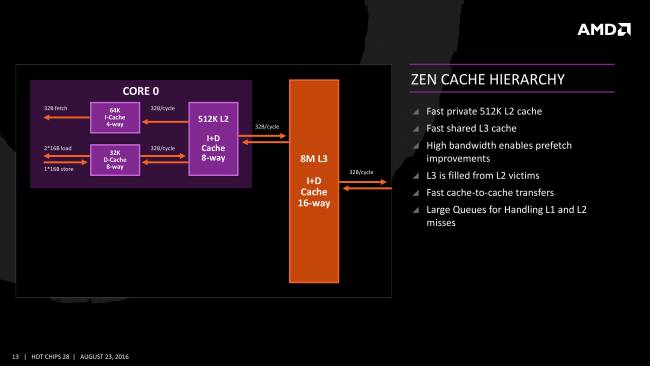
Si on récapitule rapidement :
Tout cela concourt à atténuer les performances dans les jeux où la fréquence du CPU, du contrôleur mémoire et de la mémoire jouent un rôle important. Certes on reste bien au-delà des FX, mais un cran sous Intel. Des tests d'overclocking réalisés en touchant le bus initial permettent de faire grimper la fréquence interne du contrôleur mémoire, et cela permet d'augmenter les perfs en jeu en réduisant logiquement les latences. Mais il y a une question qui reste en suspens !
On ne pourra donc pas améliorer le fonctionnement du cache L3 par un BIOS (plutôt par un scheduler de l'OS optimisé aux petits oignons pour éviter que les processus ne se promènent d'un coeur à l'autre, et surtout d'un CCX à l'autre en fonction de la météo et de l’alignement planétaire). Eh bien si on se focalise sur les R5 et R3, on n'a pas plus de réponses qu'avec le R7. Pourquoi ? Parce que simplement dans les R5 il y a deux types de puces, des 6 coeurs et des 4 coeurs. La messe semble dite pour les 6 coeurs qui devraient fort logiquement avoir les mêmes limitations que les R7. AMD pourrait très bien faire un CCX complet et un autre de 2 coeurs, ou deux CCX de 3 coeurs actifs, mais dans tous les cas de figure, il faudra que les 2 CCX communiquent. Pour ce qui est des R5 à 4 coeurs voire des R3, la facilité voudrait que ce ne soient que des puces ayant un seul CCX. Mais AMD n'aura pas forcément envie de se priver de puces exploitables à 4 coeurs actifs, tant pis pour nous si ces derniers le sont au sein de 2 CCX distincts. Tant que le géant n'aura pas communiqué sur la composition du die des R5 à 4 coeurs et des R3 (un die différent de celui des R7 n'utilisant qu'un seul CCX ?), on ne pourra pas statuer sur les performances en jeu de ces CPU.
Alors ces R7 sont pour qui ? Il y a des gens qui se satisferont largement de leur puissance qui rivalise vraiment avec les processeurs Intel, l'efficacité du multithreading étant similaire à celle de l'Hyperthreading (guettez CDH pour voir). Pour jouer, il faudra se contenter de moins de pêche, mais rien n'est cette fois rédhibitoire comme ça pouvait l'être avec les FX Bulldozer. Si en plus vous êtes équipés en moniteur Adaptive Sync, ça sera transparent pour vous ! Les joueurs par contre seraient inspirés d'attendre Q2 pour les R5, ou H2 pour les R3 et voir comment ils se comportent comparativement aux R7. Et puis il y a le prix, et tel qu'il est annoncé, il est adouci par rapport à l'offre concurrente.

Quel casse-tête !
| Un poil avant ?De l'AM4 aussi chez Scythe | Un peu plus tard ...Une MSi Gaming X GTX 1080Ti, c'est normal ! | |





















