Processeur graphique Intel Gen11 : le point architectural |
• 11 Juin 2019 à 19h17 • 22855 vues



Processeur graphique Intel Gen11 : le point architectural |
• 11 Juin 2019 à 19h17 • 22855 vues
Pour continuer dans notre série de dissections des entrailles de bouzins à base de transistors, voici venue la version GPU (n'espérez pas en avoir régulièrement, ces analyses sont conditionnées au bon vouloir des whitepapers des firmes), avec une sympathique communication de la part d'Intel sur sa future Gen11. Pour rappel, cet iGPU est prévu pour seconder les CPU Ice Lake, au moins dans certaines gammes. Certes, cela ressemble davantage à un pré-paper launch du fait d'une production en 10 nm incertaine, mais a au moins le mérite de clarifier le contenu du futur produit.
Commençons par les bases : un GPU et, comme un CPU, composé de cœurs généralistes, c'est-à-dire capables d'effectuer les opérations arithmétiques de base (addition, multiplication, etc, sur des entiers et des flottants) et de la logique booléenne (branchement, ou logique, et logique). Si vous n'avez rien bité, pas de souci : en un mot, un GPU peut théoriquement lancer n'importe quel programme. Mais, au contraire des CPU, les cœurs GPU sont optimisés pour prendre le moins d'espace possible : ils sont ainsi de type in-order (ils exécutent exactement le code qu'on leur donne, dans l'ordre, instruction par instruction), ce qui permet d'en caser un nombre faramineux (4352 pour une RTX 2080 Ti, 3840 pour une Radeon VII et... 64 dans notre Gen11, nous verrons pourquoi juste après. Avec une telle optimisation de place, la parallélisation est totalement différente : tous les cœurs d'un même groupe logique (dépendant de l'architecture) exécutent en règle générale peu ou prou la même séquence d'instructions : il faut donc des calculs très homogènes pour obtenir des performances décentes. Comment cela se concrétise-t-il ? Hé bien, si vous devez calculer une déformation de texture, c'est très rapide, car chaque pixel de l'image finale correspond à un morceau de l'image original, mais tous sont transformés de la même manière. À l'inverse, pour du Ray Tracing, il est plus difficile d'exprimer du parallélisme lorsqu'il s'agit de déterminer quel rayon frappe quel objet : en fonction du rayon, celui-ci peut s'arrêter très tôt, rebondir directement ou, au contraire, se perdre à l'infini. Donc, pour deux rayons, la suite de calculs est très variable, c'est pourquoi il est difficile de trouver une formulation efficace du problème sur GPU.
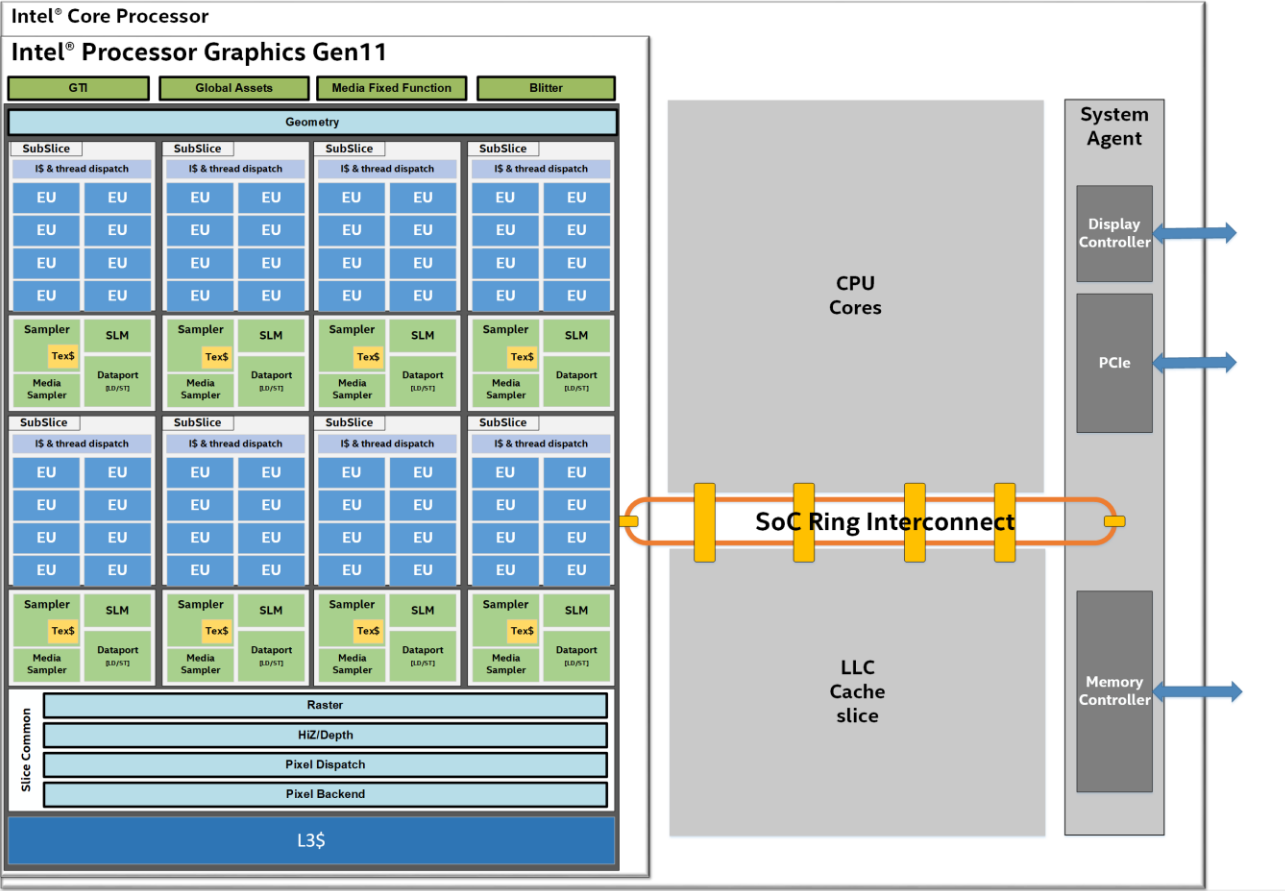
Retour maintenant à notre Gen11. Ce dernier est réparti en plusieurs niveaux : les 64 Execution Units sont rassemblées en 8 SubSlices (disons, "sous-tranches" en français), elles-mêmes formant une Slice (tranche) complète. Le tout est relié à la partie CPU par un anneau (Ring), qui se charge aussi de la communication entre les cœurs et la liaison avec le cache L3 du CPU (qui peut être utilisé par le GPU, bien que ce dernier possède son propre L3 privé. Ce design n'est pas optimal pour un grand nombre de cœurs - d'où le mesh sur le Scalable Platform - mais offre des performances satisfaisantes sur des "petites" puces à 8 cœurs physiques ou moins. On notera par ailleurs le changement de dénomination d'Intel, qui passe de "CPU" à "SoC" (System-on-Chip) : si cela est parfaitement correct techniquement, voilà une belle manière de mettre l'emphase sur le fait qu'Ice Lake ne sert pas qu'aux calculs génériques.
![Diagramme logique de la Gen11 [cliquer pour agrandir]](/images/stories/_cg/intel_gpu_igpu/intel-gen11-big-picture_t.png "La magie de la loupe, sans loupe")
Le diagramme complet de la Gen11
Commençons notre dissection par le plus général : ce qui est commun à toute la slice. On retrouve le contrôleur d'affichage (mis à jour pour l'occasion avec le support des écrans HDR), qui est physiquement proche du contrôleur mémoire pour des raisons de bande passante ; mais aussi un L3 réservé aux données de 3 Mo. Ce n'est pas tout : du silicium dédié à la rastérisation (le fait de convertir les polygones à afficher en pixels), au choix de l'affichage ou non d'une texture en fonction de sa position physique selon une coordonnée (on parle de Z Buffer) et ce qui se rapproche le plus d'un ordonnanceur assignant aux threads une subslice, nommé Pixel Dispatch, sont également de la partie. Si chacun de ces petits bidules a évolué, il ne s'agit pas de changements structurels et pour cause : leur tâche est bien définie et bien plus simple que les autres étapes du rendu.
Au sein d'une subslice, les choses s'emmêlent un peu : un ordonnanceur est aussi de la partie pour répartir les instructions sur les EU et une petite zone mémoire de 64Ko nommée Shared Local Memory (SLM), partagée entre toutes les unités, est présente. Dans la pratique, celle-ci est utilisée principalement comme cache pour des données statiques, i.e. qui restent inchangées au cours de l'exécution du programme. C'est également à cette échelle que sont gérés les chargements de textures par le Texture Sampler, et l'unité de chargement mémoire, nommé Dataport, qui interagit directement avec le L3. Avec une unité pour 8 EU, on comprend qu'il vaut mieux que les cœurs travaillent tous sur des données proches en mémoire ! Quant au media sampler, il s'agit de fonctions prédéfinies servant essentiellement à intégrer des routines bas niveau pour du décodage matériel de flux vidéos comme du VP9, utilisé sur YouTube, ou du HEVC.
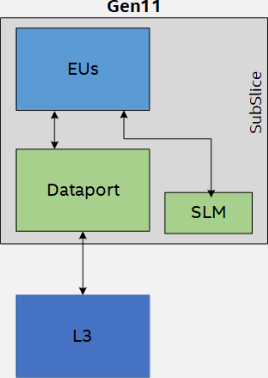
Pour la mémoire comme l'écologie, privilégiez le local !
Et enfin, le plus croustillant : ces fameuses Execution Units. Surprises : elles ne sont pas si simples qu'attendues ! En effet chaque cœur comprend deux unités vectorielles étrangement nommées ALU (dans la terminologie CPU, cela correspond davantage au calcul entier...) capable de calculer sur 4 flottants 32-bit en parallèle, ou 8 valeurs en FP16. Sachant qu'il leur est aussi possible de faire des multiplications avec accumulation (plus et fois à la suite, aussi appelées FMA) en un cycle, cela donne 16 opérations flottantes par cycle par unité en FP32, et 32 en FP16. Instant matheux : 16 opérations x 64 cœurs x 1,1 GHz = 1126,4 GFLOPS soit un chouille plus du sacro-saint TFLOPS annoncé, youpi ! Pour maximiser l'utilisation de ces unités, les EU sont hyperthreadées - un moyen très probable pour Intel d'étaler son savoir-faire à ce niveau. Point de faille de sécurité, mais une gestion très simple des deux ALUs afin de maximiser leur utilisation en fonction de la charge de travail demandée par plusieurs threads simultanément. Et attention : il ne s'agit pas de deux threads par cœur comme un CPU, mais de sept threads en même temps par EU !
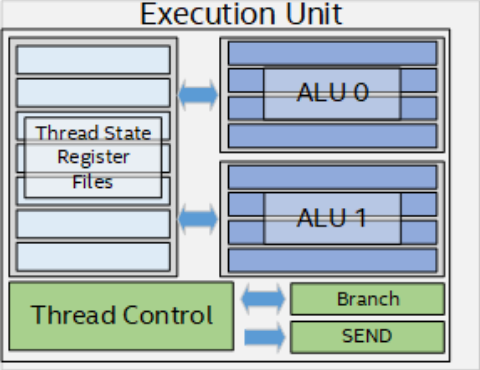
Terminons sur une note d'avenir : si cette Gen11 n'est pas de la famille Xe, il existe bien des blocs logiques qui seront commun, et cette architecture peu bien se prendre comme un avant-goût des solutions graphiques dédiées, dixit Raja Koduri lui-même. Quelles évolutions seront alors au programme ? Bien informé est celui qui pourra le déduire, mais nous voyons mal Intel rentrer en demi-teinte sur un nouveau segment comme celui-là. Encore faut-il que le processus de gravure soit, lui aussi, prêt... (Source des schémas et informations : Intel)
| Un poil avant ?Les cartes mères X570 ne seront pas données ! | Un peu plus tard ...Et un benchmark PCIe 4.0 chez UL ! | |





















